染色体の進化
染色体の本数は種によって違っていて、進化の過程で、融合したり、分裂したりしてきたと考えられる。現在、いくつかの種では、染色体単位でゲノム配列が決定されているので、異種間の染色体を比較して、染色体が、どう変化してきたのか、見てみようと思った。
ゲノム配列がまだ解読されてなかった1996年のレビュー
人類の染色体進化研究の現状
https://doi.org/10.1537/ase.104.355
の要約には、
ヒトの染色体進化は, かつてはバンド・パターンを指標とした近縁霊長類との比較により研究されてきた。 しかし最近では, 遺伝子工学的手法によるDNAレベルでの染色体比較研究が主流となっている。
とある。第一文は、多分、染色体の分染法に基づく染色パターンの比較のことを言ってるのだろう。1968年に、Q分染法が発表され、1971年に、G分染法が考案されたらしい。第二文で言及されてる手法は、上レビューのテーマであるFISH(fluorescence in situ hybridization)法のことと思う。当時は、こうして得られる限られた情報を使って、染色体が、どのように変化してきたか推測していたらしい。
レビュー中の図4を見ると、ヒトと、6種の哺乳類の染色体の対応関係を示している。2020年代の現在は、ここに挙げられている動物は、染色体単位で、塩基配列が決定されているので、ずっと詳細な情報を、数時間で得ることができる。更に、近縁の哺乳類だけでなく、もっと遠いニワトリやトカゲとの比較もできる。
そういう論文は沢山出ているけど、読むのが面倒なので、自分で適当に実験していく。
例えば、ヒトとアカゲザル(学名Macaca mulatta、日本では外来種とされるが、ニホンザルと交雑するらしい)の比較をしてみる。やることは、それぞれの各染色体同士のアラインメントの作成。アラインメントには、LASTZを使った。
LASTZ
https://github.com/lastz/lastz
make lastz_32でビルドされるLASTZ_32というのも入れておく。最新のバージョンは、1.04.15だったので、それを使用。
ゲノム配列は、UCSCの以下のURLからダウンロード。
Sequence and Annotation Downloads
https://hgdownload.soe.ucsc.edu/downloads.html
ヒトは、hg38が最新。アカゲザル(一般名はRhesus macaque)は、rheMac10が最新。hg38.faとかrheMac10.faは、複数の配列を含んでるので、一ファイル一配列に分割しておく。染色体以外の配列chrUn*とか、chr*randomとかあるけど、それらは除外しておく。ミトコンドリアの配列もあるけど、不要なら消しておく。それぞれの配列ファイルを、hg38とrheMac10ディレクトリに置いたとして、以下のようなコマンドで、アラインメントを作成した。
spc1=hg38
spc2=rheMac10
for f in `ls ${spc1}`;do
for f2 in `ls ${spc2}`;do
lastz_32 ${spc1}/$f ${spc2}/$f2 --notransition --step=20 --nogapped --format=general:nmismatch,name1,strand1,start1,end1,size1,name2,strand2,start2,end2,size2 > ${spc1}_vs_${spc2}/${spc1}_`basename $f .fa`_${spc2}_`basename $f2 .fa`.out
done
doneこれで、mismatchは許すが、gapは許さない(ラフな)アラインメントができる。一致しない塩基同士がある時、gapになるか、mismatchになるかは、penalty次第だけど。
このアラインメントを可視化するために、ドットプロットを作る。以下のような実装を作った
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
import os,sys
#-- dot plot for single ".out" file
def dotplot(filepath , threshold=1000):
Nunit = 1000000 #-- per Mb
dat = []
size1,size2 = 0,0
name1,name2="",""
for line in open(filepath):
line = line.strip()
if len(line)==0 or line[0]=="#":continue
ls = line.split()
if len(ls)<10:continue
name1,name2 = ls[1],ls[6]
s0,e0 = int(ls[3]),int(ls[4])
s1,e1 = int(ls[8]),int(ls[9])
size1 = int(ls[5])
size2 = int(ls[10])
if ls[2]=="-":s0,e0=size1-e0,size1-s0
if ls[7]=="-":s1,e1=size2-e1,size2-s1
if ls[2]==ls[7]:
dat.append( (s0,e0,s1,e1,+1) )
else:
dat.append( (s0,e0,s1,e1,-1) )
if len(dat)==0:return
fig, ax = plt.subplots()
dat.sort(key=lambda x:x[-1])
ax.set_xlim(0 , size1/Nunit)
ax.set_ylim(0 , size2/Nunit)
ax.set_xlabel("{0} (Mb)".format(name1))
ax.set_ylabel("{0} (Mb)".format(name2))
ax.xaxis.set_major_locator(MaxNLocator(integer=True))
ax.yaxis.set_major_locator(MaxNLocator(integer=True))
#ax.set_aspect('equal')
for s0,e0,s1,e1,dd in dat:
if e0-s0 < threshold:continue
if dd==+1:
ax.plot([s0/Nunit,e0/Nunit],[s1/Nunit,e1/Nunit],color="red")
else:
ax.plot([s0/Nunit,e0/Nunit],[e1/Nunit,s1/Nunit],color="blue")
plt.savefig("{0}.png".format(filepath))
plt.close()
#plt.show()
def make_dotplot(dirpath , threshold=1000):
for f in os.listdir(dirpath):
dotplot(os.path.join(dirpath,f) , threshold)
if __name__=="__main__":
make_dotplot(sys.argv[1])
thresholdは、ヒトとチンパンジーのように近縁種の場合は、似た配列が沢山あるのと、プロット量が多いので、1000でいいけど、近縁でない種の場合は、もっと小さい数値(例えば、0)にしないと、対応関係が見えない。
冒頭の総説を見ると、ヒトの2番染色体は、ニホンザルの9番と15番染色体に対応してるとある。染色体番号の付け方が違うようで分かりづらいが、アカゲザルでは、多分、chr12,chr13と対応してる。ヒトの2番染色体は、他の大型類人猿が持つ2本の染色体が融合して生じたと考えられている。UCSCにあるチンパンジーゲノム配列では、chr2Aとchr2Bという名前になってるけど、チンパンジーのchr2Bとアカゲザルのchr13が対応する染色体らしい。
ヒトの2番染色体は、ブタでも2本の染色体に対応してるので、ブタとサルのMRCA(Most Recent Common Ancestor)に於いても、2本の染色体だったのだろうと思われる。ブタ(susScr11)のchr3とchr15は、チンパンジーのchr2A,chr2Bと、それぞれ相同性がある。
冒頭のレビュー図4によると、ニホンザルの7,13番染色体は、ヒト染色体では、14,15番染色体と20,22番染色体に対応している。ニホンザルの7,13番染色体は、アカゲザルでは、chr7とchr10に相当すると思われる。例えば、アカゲザルの7番染色体とヒト14,15番染色体間のドットプロットは以下のようになった。


赤い部分は傾きが正で、同一strand。青い部分は傾きが負で、strandが逆になってる部分を表す。ゴリラの17番染色体とヒトの5番染色体のドットプロットは、以下のようになっている。

ドットプロットは全部作ったけど、数が多いので他は省略。
ドットプロットを目で見ると、染色体が、どう再編成したかアタリが付く。gapなしのアラインメントは、アラインメントされない領域が多すぎるし、また複数箇所にマップされることも多いので、以下のようなコマンドで、なるべく広範囲の精密なアラインメントを行う。
s1=(1 2 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22)
s2=(1 12 13 2 5 6 4 3 8 15 9 14 11 17 7 7 20 16 18 19 10 3 10)
for i in "${!s1[@]}"; do
lastz_32 hg38/chr"${s1[$i]}".fa rheMac10/chr"${s2[$i]}".fa --chain --gfextend --gapped --step=20 --format=maf > hg38_vs_rheMac10/pairs_$i.maf
doneこっちの方が、計算時間は長いので、gapなしのアラインメントで、染色体対応関係のアタリを付けておくのは、計算時間の短縮のために有益。
以前に、大型類人猿間で、同じオプションで、ゲノム間アラインメントを作って、ミスマッチ率を計算したけど、ゴリラの染色体再編成を考慮したり、以前は、2A染色体と2B染色体を結合して、ヒト2番染色体と比較してたのを、それぞれ別々にやって計算し直したのが以下の表。ついでに、指標を追加した。
| 種1 | 種2 | 染色体 | アライン長(bp) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | umm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | umm率(%) | dmm数(bp) | dmm率(%) | cmm数 |
| hg38 | panPan3 | 常,X | 2678735571 | 41576138 | 31189401 | 2717358723 | 1.53 | 6758108 | 4406603 | 503091302 | 1.34 | 3215657 | 0.12 | 2456798 |
| hg38 | panTro6 | 常,X | 2699947183 | 44404643 | 33778773 | 2751026993 | 1.61 | 6483380 | 4236391 | 484545618 | 1.34 | 3925816 | 0.14 | 2971884 |
| panTro6 | panPan3 | 常,X | 2686365237 | 16904614 | 16975214 | 2726251998 | 0.62 | 3021545 | 2565225 | 688400052 | 0.44 | 1775208 | 0.07 | 1243923 |
| 種1 | 種2 | 染色体 | アライン長(bp) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | umm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | umm率(%) | dmm数(bp) | dmm率(%) | cmm数 |
| hg38 | gorGor6 | 常,X | 2626582175 | 48739956 | 33858948 | 2652779980 | 1.84 | 8802977 | 5360986 | 511789105 | 1.72 | 3440313 | 0.13 | 2693551 |
| panTro6 | gorGor6 | 常,X | 2565732892 | 47670060 | 31548473 | 2590652189 | 1.84 | 9707027 | 5614943 | 566282817 | 1.71 | 3297893 | 0.13 | 2606152 |
| panPan3 | gorGor6 | 常,X | 2533630218 | 47149463 | 31197440 | 2559477278 | 1.84 | 9437399 | 5462824 | 551406301 | 1.71 | 3284119 | 0.13 | 2591233 |
| 種1 | 種2 | 染色体 | アライン長(bp) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | umm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | umm率(%) | dmm数(bp) | dmm率(%) | cmm数 |
| hg38 | ponAbe3 | 常,X | 2588246045 | 93093484 | 57653867 | 2625495453 | 3.55 | 15351101 | 8323644 | 460620083 | 3.33 | 8341840 | 0.32 | 6876853 |
| panTro6 | ponAbe3 | 常,X | 2487178819 | 89772146 | 53999989 | 2522771809 | 3.56 | 15455544 | 8213412 | 461475178 | 3.35 | 8063035 | 0.32 | 6647953 |
| panPan3 | ponAbe3 | 常,X | 2482052601 | 89520144 | 53594491 | 2518426197 | 3.55 | 15632330 | 8300557 | 466525516 | 3.35 | 7960499 | 0.32 | 6599212 |
| gorGor6 | ponAbe3 | 常,X | 2498049196 | 89470029 | 52566349 | 2528024398 | 3.54 | 16011592 | 8387101 | 476595807 | 3.36 | 7725178 | 0.31 | 6452555 |
アライン長:アラインメントされた配列の長さの合計(オーバーラップしてる場合、重複カウントなし)
mm数:アラインメントのmismatch数
gap数:アラインメントのgap数
延べアライン長:アラインメントされた配列の長さの合計(オーバーラップしてる場合、重複してカウント)
mm率:mm数/延べアライン長
umm数:一意にmapされた領域のmismatch数
一意gap数:一意にmapされた領域のgap数
一意アライン長:一意にmapされた領域の長さ合計
umm率:一意mm数/一意アライン長
dmm数:2bp連続でmismatchがある箇所の個数。dmmは私が作った造語
dmm率:dmm数/延べアライン長
cmm数:連続してmismatchがある領域の個数
SNV(single nucleotide variant)が完全にランダムな場所に落ちるなら、dmm率は、mm率の2乗に近い値になるはずだけど、そうはなってなくて、近縁種ほど、乖離が大きい。表にはないけど、一意にアラインされた領域でも、ほぼ同じなので、複数箇所にアラインメントを許してることに起因するartifactとかではなさそうに思える。
cmm数は、ミスマッチが、3つ以上続く領域が沢山ある可能性を排除するために測定したもの。1+(dmm数/cmm数)で、2つ以上ミスマッチが続く領域の平均長が分かる。
SNVがランダムに落ちるわけでないのは、染色体ごとのmm率のバラツキを漫然と眺めてても何となく分かるけど、単一の指標があった方が理解しやすい。染色体ごとに、dmm率を計算してみると、各染色体でも、SNVの入りやすい領域と、そうでない領域が存在してるらしいことが分かる。dmm率/(mm率の2乗)を計算すると、ゲノム単位と染色体単位で、それほど差はない。
アカゲザル(rheMac10)と大型類人猿の間で、同様に比較すると、以下のようになってた。
| 種1 | 種2 | 染色体 | アライン長(bp) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | umm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | umm率(%) | dmm数(bp) | dmm率(%) | cmm数 |
| hg38 | rheMac10 | 常 | 2285895996 | 156162266 | 141741288 | 2338797775 | 6.68 | 29669259 | 22429338 | 468373954 | 6.33 | 20826992 | 0.89 | 16735778 |
| panTro6 | rheMac10 | 常 | 2004548986 | 137987342 | 124474482 | 2053284974 | 6.72 | 26716942 | 20069769 | 419761766 | 6.36 | 18546755 | 0.90 | 14883475 |
| panPan3 | rheMac10 | 常 | 2004762223 | 137329895 | 123850821 | 2051694693 | 6.69 | 26673714 | 20026072 | 419686539 | 6.36 | 18326651 | 0.89 | 14743807 |
| gorGor6 | rheMac10 | 常 | 1927929371 | 131494040 | 117016510 | 1969649600 | 6.68 | 25746189 | 19215645 | 403458141 | 6.38 | 17380587 | 0.88 | 14026091 |
| ponAbe3 | rheMac10 | 常 | 2138375821 | 147872816 | 133646631 | 2190175646 | 6.75 | 30374712 | 22559771 | 474878246 | 6.40 | 19909886 | 0.91 | 15991518 |
ミスマッチ率が、ほぼ等しいので、大型類人猿で、SNV獲得速度に差は、殆どなかっただろうと思う。もっと遡るために、新世界ザルであるコモンマーモセット(calJac4)との比較を行う。
| 種1 | 種2 | 染色体 | アライン長(bp) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | umm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | umm率(%) | dmm数(bp) | dmm率(%) | cmm数 |
| rheMac10 | calJac4 | 常 | 1959286889 | 231664102 | 252003127 | 2023901958 | 11.45 | 53629550 | 51874175 | 481270165 | 11.14 | 43922606 | 2.17 | 33976695 |
| hg38 | calJac4 | 常 | 1879486713 | 209382873 | 227920796 | 1934888846 | 10.82 | 47766735 | 46318223 | 453739763 | 10.53 | 38202814 | 1.97 | 29807236 |
| panTro6 | calJac4 | 常 | 1823134238 | 203598006 | 220695032 | 1878129858 | 10.84 | 46686827 | 45009615 | 442227433 | 10.56 | 37174828 | 1.98 | 29001488 |
| panPan3 | calJac4 | 常 | 1814251852 | 202007402 | 218818327 | 1867886607 | 10.81 | 46362676 | 44768625 | 439965764 | 10.54 | 36788720 | 1.97 | 28721677 |
| gorGor6 | calJac4 | 常 | 1794640696 | 198573615 | 213752368 | 1844481101 | 10.77 | 45878734 | 44005838 | 436158798 | 10.52 | 35847561 | 1.94 | 28066581 |
| ponAbe3 | calJac4 | 常 | 1959775525 | 218832288 | 237063460 | 2017994375 | 10.84 | 51280402 | 49461086 | 486281052 | 10.55 | 39960867 | 1.98 | 31190420 |
アカゲザルとコモンマーモセットの間のミスマッチ率は、大型類人猿とコモンマーモセットの間のミスマッチ率より高そうなので、アカゲザルは、大型類人猿より、一年あたりのSNV得速度が早い可能性が推測される。アカゲザルは、大型類人猿より性成熟が早く、寿命もやや短いようなので、一世代あたりのSNV獲得量自体は、同水準なのかもしれない。
染色体対応関係とコマンドは、以下のような感じ。
s1=(1 1 1 2 2 3 3 3 4 5 6 7 8 8 9 10 10 11 12 13 13 14 15 15 16 16 17 18 19 20 21 22)
s2=(18 19 7 14 6 15 17 21 3 2 4 8 13 16 1 12 7 11 9 1 5 10 10 6 12 20 5 13 22 5 21 1)
for i in "${!s1[@]}"; do
lastz_32 hg38/chr"${s1[$i]}".fa calJac4/chr"${s2[$i]}".fa --chain --gfextend --gapped --step=20 --format=maf > hg38_vs_calJac4/pairs_$i.maf
dones1=(1 1 1 2 2 2 3 3 3 4 5 6 7 7 8 8 9 9 10 10 11 12 13 14 15 16 17 17 18 19 20 20)
s2=(18 19 7 15 17 21 2 21 8 4 3 2 10 6 13 16 12 7 1 5 9 6 14 11 1 5 1 5 13 22 12 20)
for i in "${!s1[@]}"; do
lastz_32 rheMac10/chr"${s1[$i]}".fa calJac4/chr"${s2[$i]}".fa --chain --gfextend --gapped --step=20 --format=maf > rheMac10_vs_calJac4/pairs_$i.maf
done
まぁ、とりあえず、1996年の総説にあったような染色体進化の追試は、大分簡単にできるようになった(結論)。
現在、サル目の分類は、以下のようになっているらしい。上記で比較したサル目の動物は、全部、真猿に含まれる。
---- サル目 ------------------ 曲鼻亜目 -------- キツネザル下目
| |
| └-- ロリス下目
|
|
└------- 直鼻亜目 -------- メガネザル下目
|
|
└-- 真猿下目 ---------- 新世界ザル
|
|
└----- 旧世界ザル(オナガザル上科)
|
|
└-- 類人猿(ヒト上科) ----------- 小型類人猿(テナガザル科)
|
└----- 大型類人猿(ヒト科) 系統が遠くなるにつれて、アラインメントされる長さも減ってる。こういう比較が、どれくらいまで使えるのか調べようと思って、脊索動物の幅広い種で、gapなしのアラインメントした。ドットプロットを見てると、系統的に遠い種では、大きな相同領域があることは期待できないけど、もう少し定量的に把握するために、coverageを計算した。
種1と種2のゲノムをgapなしで、アラインメントして、種1のゲノム配列の内、種2のどこかにマッピングされた領域の長さが、種1のゲノム全長の何%に相当するかを被覆率1、同様に、種1のどこかにマッピングされた領域の長さが、種2のゲノム全長の何%に相当するかを被覆率2として集計したのが以下の表。
ゲノム配列は、基本的に、UCSCにリンクがあるのを使ったけど、ハリモグラはなかったし、ジャイアントパンダは古かったので、以下でゲット
mTacAcu1.pri
https://www.ncbi.nlm.nih.gov/assembly/GCF_015852505.1/
Ailuropoda melanoleuca (giant panda)
https://www.ncbi.nlm.nih.gov/assembly/GCF_002007445.2
| 種1 | 種2 | 被覆率1(%) | 被覆率2(%) | 通名1 | 通名2 | |
| hg38 | panTro6 | 42.95 | 51.67 | ヒト | チンパンジー | |
| hg38 | panPan3 | 42.49 | 64.33 | ヒト | ボノボ | |
| hg38 | gorGor6 | 41.76 | 53.61 | ヒト | ゴリラ | |
| hg38 | ponAbe3 | 41.60 | 38.70 | ヒト | オランウータン | |
| hg38 | rheMac10 | 39.24 | 45.24 | ヒト | アカゲザル | |
| hg38 | nomLeu3 | 39.95 | 40.57 | ヒト | テナガザル | |
| hg38 | calJac4 | 30.47 | 37.20 | ヒト | マーモセット | |
| hg38 | oryCun2 | 4.35 | 6.90 | ヒト | ウサギ | |
| hg38 | mm39 | 2.67 | 3.87 | ヒト | マウス | |
| hg38 | rn7 | 2.62 | 5.93 | ヒト | ラット | |
| hg38 | canFam6 | 6.14 | 15.01 | ヒト | イヌ | |
| hg38 | felCat9 | 6.61 | 7.20 | ヒト | ネコ | |
| hg38 | ailMel3 | 4.88 | 6.19 | ヒト | パンダ | |
| hg38 | bosTau9 | 5.54 | 9.58 | ヒト | 牛 | |
| hg38 | susScr11 | 5.74 | 6.73 | ヒト | ブタ | |
| hg38 | monDom5 | 1.33 | 1.09 | ヒト | オポッサム | |
| hg38 | tacAcu1 | 0.76 | 1.36 | ヒト | ハリモグラ | |
| hg38 | ornAna2 | 0.24 | 1.42 | ヒト | カモノハシ | |
| hg38 | galGal6 | 0.49 | 2.46 | ヒト | ニワトリ | |
| hg38 | xenLae2 | 0.30 | 0.48 | ヒト | アフリカツメガエル | |
| hg38 | danRer11 | 0.21 | 2.10 | ヒト | ゼブラフィッシュ | |
| hg38 | oryLat2 | 0.15 | 0.91 | ヒト | メダカ | |
| hg38 | ci3 | 0.01 | 0.29 | ヒト | ユウレイボヤ | |
| panTro6 | panPan3 | 46.23 | 52.19 | チンパンジー | ボノボ | |
| felCat9 | oryCun2 | 4.06 | 4.78 | ネコ | ウサギ | |
| felCat9 | canFam6 | 19.62 | 44.92 | ネコ | イヌ | |
| canFam6 | ailMel3 | 20.46 | 11.49 | イヌ | パンダ | |
| bosTau9 | susScr11 | 11.73 | 12.15 | ウシ | ブタ | |
| bosTau9 | canFam6 | 7.21 | 13.95 | ウシ | イヌ | |
| susScr11 | felCat9 | 8.66 | 10.36 | ブタ | ネコ | |
| ornAna2 | tacAcu1 | 28.69 | 8.67 | カモノハシ | ハリモグラ | |
| ornAna2 | monDom5 | 1.64 | 0.10 | カモノハシ | オポッサム | |
| mm39 | rn7 | 23.94 | 31.21 | マウス | ラット | |
| rn7 | felCat9 | 2.73 | 3.73 | ラット | ネコ | |
| rn7 | monDom5 | 1.09 | 0.55 | ラット | オポッサム | |
| galGal6 | ornAna2 | 0.33 | 0.34 | ニワトリ | カモノハシ | |
| galGal6 | anoCar2 | 0.81 | 0.19 | ニワトリ | グリーンアノール | |
| fr3 | oryLat2 | 5.05 | 2.74 | フグ | メダカ | |
| fr3 | gasAcu1 | 7.58 | 6.22 | フグ | トゲウオ | |
| oryLat2 | gasAcu1 | 3.45 | 9.97 | メダカ | トゲウオ | |
| danRer11 | fr3 | 0.64 | 2.83 | ゼブラフィッシュ | フグ |
ここで算出されたcoverageの絶対的な数字自体に、さほどの意味はないけど、系統的に近い種同士だと、被覆率が高くなる傾向は見て取れ、目安程度にはなる。
ヒトと他のサル目は被覆率が高いし、同じネコ目に属するイヌとネコ、ネズミ目に属するマウスとラットも被覆率が高い。ウシとブタは、鯨偶蹄目に分類されている。パンダもネコ目に属し、ヒトよりは、イヌやネコに近そう。パンダが、どれくらいクマか算出したかったけど、染色体の配列まで決定されたクマのゲノムがなかった。哺乳類の中でも、単孔目のカモノハシやハリモグラくらいまで行くと、ヒトと比較した時の被覆率は大分低い。
ニワトリと爬虫類のグリーンアノールは、あんまり似てないっぽいけど、現行の爬虫類の中で、トカゲやヘビを含む有鱗目は、鳥類から遠い系統で、最も近いのは、ワニ目とされている。最近は、以下のような系統関係が支持されてるらしい。
------------ 有鱗目(ヘビ、トカゲ、ミミズトカゲ)
|
----------------|
| |
| ------------ ムカシトカゲ目
---- 爬虫類 -------|
| ------------ カメ目
| |
----------------|
| --------- ワニ目
------------|
--------- 鳥類この系統関係が正しければ、多分、ワニとトカゲも、ゲノムは、それほど似てないと思われる。現在、利用可能なワニゲノムは、アメリカアリゲーターのもので、染色体スケールで配列が決定されてなかったので、今回は保留。単純なゲノム全体の相同性で分類するなら、ヘビ・トカゲ。ムカシトカゲと、カメ・ワニ・鳥に分けるほうが理に適ってるのかもしれない。とりあえず、ニワトリとグリーンアノールの比較結果も妥当ではあるんだろう。
鳥は特徴的な外見(嘴、羽毛、翼など)で区別できるので、ワニがトカゲと鳥に近いか質問して、鳥と答える人はいないだろうし、何の知識もない3歳児に、色んな生物種を提示して鳥か鳥でないかクイズを実施しても、あんまり間違えなさそうに思える(コウモリを鳥と答える子供はいるかもしれないけど)。なので、鳥に固有の配列を探索したという研究もある。
ゼブラフィッシュは、コイ目で、骨鰾上目に含まれる。フグはフグ目、メダカはダツ目で、トゲウオ(≠トビウオ、トビウオはダツ目)はトゲウオ目で、フグ目とダツ目とトゲウオ目は、棘鰭上目に分類されている。
数字で見ると、ヒトとアフリカツメガエルは、それほど似てないけど、ドットプロットを見ると、マッピングされた領域が、かなり広い範囲で一直線上に綺麗に並んでることが、割とある。以下は、ヒト4番染色体とアフリカツメガメル1S染色体のドットプロット
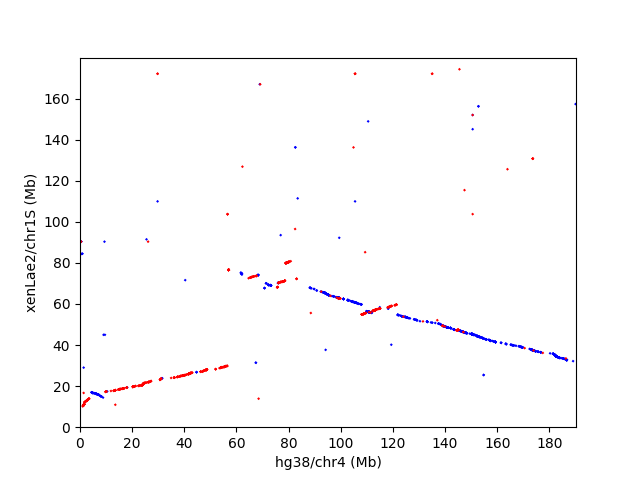
画像で見ると、凄く密に相同配列がありそうに見えるけど、これは可視化の仕方の問題で、拡大すると、相同配列は、もっと、まばらにしかないことが分かる。以下は、上のドットプロットの一部を拡大したもの。

ヒトと魚くらいになると、そのような領域は、もっと断片的にしか存在しない。もっと遠い種との間でも、遺伝子の並び順は保存されてたりするらしく、このことを指してシンテニーとか呼ぶ(Hox geneクラスターみたいなもん?)。シンテニーの解析から、脊索動物の系統関係を推測したりしてる論文もある。
The amphioxus genome and the evolution of the chordate karyotype
https://doi.org/10.1038/nature06967
人類の起源
ふと、ヒトと類人猿のゲノムを比較したことがないので、やってみようと思った。
単にアラインメントするだけでは詰まらないので、人類と、チンパンジー、ボノボの分岐時期の推定に役立ちそうな指標を集計することにする。チンパンジーとボノボの分岐は、人類の分岐より後とされているので、ヒトとチンパンジーの"違い"、ヒトとボノボの"違い"は、同程度になっていると考えられる。
最初に、既存の報告を眺めておく。
TIMETREE
http://www.timetree.org/
というサイトによると、人類が、チンパンジー、ボノボとの共通祖先と分岐した時期は、79の研究に基づく中央値が640万年。信頼区間(?)は、510万年〜1180万年となっている(どういうモデルに基づいて計算された区間か知らないけど、あくまで多くの報告が、このあたりに集中しているというだけで、95%の確率で正しいとかいう類のものではないと思う)。
最も古い予測は、1億3900万年となっていて、多分、何かの間違い(?)。次点は1480万年。1480万年は、2012年の論文に書いてあるらしいので、それほど古い研究でもない。2010年以降の報告に限っても、550〜1480万年と、まだ幅は大きい。2010年以降の報告は30件あって、その中で、1000万年を超えるのは、(1億3900万年のも含めて)4件。とはいえ、少数派だから正しくないとは、当然言えない。
同じサイトで、チンパンジーとボノボの分岐を調べると、39の研究に基づく中央値が240万年で、信頼区間は238.9万年〜315.7万年前となっている。一番古い予測分岐年代は、610万年前で、一番新しい方は80万年前。日本語で調べると、チンパンジーとボノボ分岐年代は、80〜200万年前としているものが多く出てくるけど、典型的な見積もりとは言えないことになる。この見積もりが出回っている理由は分からない。
ついでに、チンパンジーとボノボは、現代でも、交配可能らしい。
Hybrids between common chimpanzees (Pan troglodytes) and pygmychimpanzees (Pan paniscus) in captivity
https://lirias.kuleuven.be/1914867
一般的に、種の分岐時期の推定法は、化石年代による方法と、分子時計による方法がある。化石年代による推定は、個人で追試するのはほぼ不可能。金と時間と発掘許可があったとしても、適当な化石が見つかるかは、運によるとところが大きい。一方、分子時計による推定は、公開されているゲノム配列を信用するなら、手の出しようはある。現在のところ、自力でゲノム配列をシーケンスするのは大変だが、金と許可があれば、原理的には、何とか出来なくはない。
分子時計は、1960年代に提案されたもので、最初は、タンパク質のアミノ酸配列を見ていた。1967年に、Vincent SarichとAllan Wilsonは、ヒトとチンパンジーの分岐時期を約500万年前と推定した。1977年に、サンガー法が考案されて、80年代には、個々の遺伝子の塩基配列やミトコンドリアの配列が比較されるようになった。
分子系統学とヒトの起原
https://doi.org/10.2142/biophys.28.119
という1988年の総説を見ると、ミトコンドリアの比較による議論が中心となっている。
2010年前後からは、多くの生物種でゲノム配列が決定されたし、コンピュータの性能も向上してたので、全ゲノム同士を比較することができるようになった。
進化の過程で、染色体は、割とよく切断したり、融合したりしているようで、哺乳類に限っても、染色体数は、最小で6から、最大で102まで幅がある。ヒトの場合、2番染色体は、かつては、2つの異なる染色体だったのが融合したと考えられていて、ヒト以外の類人猿は、ヒトより染色体が2本(一対)多く、昔の文献を見ると、チンパンジーの12,13番染色体と、ヒト2番染色体が対応してると書いてある。公開されてるゲノム配列では、分かりやすく、2A,2B染色体とされている。
染色体端部にはテロメア配列があるけど、ヒト2番染色体長腕2q13には、対向したテロメア反復配列の痕跡が見られる。
追記)あとから気付いたけど、ゴリラでは、他の大型類人猿には起こっていない染色体再編成が見られる。何が起こったのか正確にはよく分からないけど、ゴリラ5,17番染色体は、どちらも、ヒト5,17番染色体の一部を含む(5番染色体と17番染色体で環状になって切断でもしたのか?)。しかし、以下では、この再編成に気付かず、計算を進めてしまった。話の流れには影響ないので、そのままにしてある
ヒトと類人猿の場合は、染色体の対応が、よく取れるので、ゲノム全体のアラインメントをする。アラインメントには、LASTZというのを使うことにした。
LASTZ
https://github.com/lastz/lastz
make lastz_32でビルドされるLASTZ_32というのも入れておく。最新のバージョンは、1.04.15
ゲノム配列は、ヒト(hg38)、ボノボ(panPan3)、チンパンジー(panTro6)を使った。
hg38
https://hgdownload.soe.ucsc.edu/goldenPath/hg38/bigZips/
panPan3
https://hgdownload.soe.ucsc.edu/goldenPath/panPan3/bigZips/
panTro6
https://hgdownload.soe.ucsc.edu/goldenPath/panTro6/bigZips/
ゴリラとオランウータンは、gorGor6とponAbe3が、現在の最新の配列。オランウータンは、スマトラ・オランウータン(Pongo abelii)や、ボルネオ・オランウータン(Pongo pygmaeus)などが区別されてるっぽい。テナガザルゲノムは、キタホオジロテナガザル(Nomascus leucogenys)のnomLeu3が存在する。
ダウンロードしたゲノム配列は、以下のようなコードで、染色体ごとに分割しておく。
import os
def splitFasta(infile, outdir, prefix=""):
assert(os.path.exists(outdir))
lines = []
cur_name = None
for line in open(infile):
if len(line.strip())==0:
continue
elif line.startswith(">"):
if cur_name is not None:
with open(os.path.join(outdir , "{0}.fa".format(cur_name)),"w") as fp:
fp.write("".join(lines))
lines = [">" , prefix , line[1:]]
cur_name = line.strip()[1:]
else:
lines.append( line )
if len(lines)>0:
with open(os.path.join(outdir , "{0}.fa".format(cur_name)),"w") as fp:
fp.write("".join(lines))
if __name__=="__main__":
splitFasta("hg38.fa" , "hg38" , "hg38/")
splitFasta("panPan3.fa" , "panPan3" , "panPan3/")
splitFasta("panTro6.fa" , "panTro6" , "panTro6/")
cat <(echo ">panPan3/chr2") <(tail -n +2 panPan3/chr2A.fa) <(tail -n +2 panPan3/chr2B.fa) > panPan3/chr2.fa cat <(echo ">panTro6/chr2") <(tail -n +2 panTro6/chr2A.fa) <(tail -n +2 panTro6/chr2B.fa) > panTro6/chr2.fa
LASTZは、オプションの指定によって得られる結果が大きく変わる。今回は、とりあえず、可能な限り、頑張ってアラインメントしてもらうために、例えば、以下のようなコマンドを打った
for f in `ls hg38`;do lastz hg38/$f panPan3/$f --chain --gfextend --gapped --step=20 --format=maf > hg38_vs_panPan3_`basename $f .fa`.maf 2> /dev/null lastz hg38/$f panTro6/$f --chain --gfextend --gapped --step=20 --format=maf > hg38_vs_panTro6_`basename $f .fa`.maf 2> /dev/null lastz panPan3/$f panTro6/$f --chain --gfextend --gapped --step=20 --format=maf > panPan3_vs_panTro6_`basename $f .fa`.maf 2> /dev/null done
全ての染色体について、ヒトvsチンパンジー、ヒトvsボノボ、チンパンジーvsボノボのアラインメントを作成。
panTro6 vs hg38のアラインメントなんかは公開されてるっぽいのだけど、使用したオプションなどが分からないので、(同一条件で比較するために)全部やり直す。
https://hgdownload.soe.ucsc.edu/goldenPath/panTro6/vsHg38/
出力は、mafとかいうフォーマット。以下のような3行の連なりが沢山(数百〜数千個)出てくる。
a score=25092 s chr5 104915 302 + 181538259 GGTGGAGAAACACTGCACAGGGGGTGAGGGCTGTTCCAGTTCTGGTGTTCCCGTCCTGAAGGTGGAGAAACACTCCACAGTGGGTGAGGGCTGTTCTGG-TTCTGGTGTTCCCATCCTGAAGGTGGAAAAACAGTGCACAGTGGGTGAGGGCTGTTCTGGTTCTGGTGTTCCCGTCCTGAAGGTGGAGAAACACTCCACAGTGGGTGAGGGCTGTTCTGGTTTTGGTGTTCCCGTCCTGAAGGTGGAGAAACACTCCGCAGTGGGTGAGGGCTGTTCTGGGTTCTCATGCTCCTGTCTTGAAG s chr5 76020 302 + 176502593 GGTGGAGAAACACTCCACAGTGGGTGAGGGGTGTTCCAGTTCTGGTGTTCCCGTCCTGAAGGTGGAGAAACACTCCGCAGTGGGTGAGGGGTGTTCTGGGTTCTGGTGTTCCCATCCTGAAGGTGGAGAAACACTCCACAGTGGGTGAGGGCTGTTCTGGTTCTGGTGTTCCCATCCTGAAGGTGGAGAAACACTCCACAGTGGGTGAGGGCTGTTCTGGTTCTGGTGTTCCCATCCTGAAGGTGGAGAAACACTCCACAGTGGGTGAGGGCTGTTCT-GGTTCTGGTGTTCCCGTCCTAAAG
2行目は、1つ目の配列で、3行目が、2つ目の配列。完全に同一ではないが、よく似ていることは分かる。
結果を見ると、第一に、アラインメントされない領域が、割とある。ヒトvsチンパンジー、ヒトvsボノボだと、ヒトゲノムの5~10%がアラインメントされない(モノによっては、不明な塩基Nが結構含まれるが、除去して算出)。ボノボvsチンパンジーだと、アラインメントされない領域は、概ね5%未満の模様。
アラインメントされなかった配列の素性をいくつか調べると、CpGアイランドっぽいGC richな配列や謎の反復配列、レトロトランスポゾンLINE-1っぽいものがある。中には、遺伝子だと予測されてながら、他の種では、同じ場所に、相同遺伝子がないというケースもあった。ボノボの12番染色体には
LOC103786383 ATP synthase mitochondrial F1 complex assembly factor 1 [ Pan paniscus (pygmy chimpanzee) ]
https://www.ncbi.nlm.nih.gov/gene/103786383
があるけど、チンパンジーの12番染色体には、相同遺伝子がない。BLASTしてもhitしない。多分、チンパンジーでは、1番染色体にある。
ATPAF1 ATP synthase mitochondrial F1 complex assembly factor 1 [ Pan troglodytes (chimpanzee) ]
https://www.ncbi.nlm.nih.gov/gene/456558
ヒトでも相同遺伝子が1番染色体にあり、ボノボの1番染色体にも相同遺伝子があるので、元々は、1番染色体にあった遺伝子のコピーが12番染色体に挿入されるということが、ボノボだけで起こったのだと思われる。これが、発現して、何かの機能を果たしているのか、偽遺伝子なのかは分からないけど。
全体としては、LASTZは期待した結果を出しているように思われる。
第二の問題として、アラインメント元の領域に重なりがある場合がある。ゲノムには、コピーされた配列が遠く離れた場所にあったりするので、同一の配列が、複数箇所にマッチする可能性はあるけど、分子時計として使う場合、変異の個数をカウントしたいので、どのアラインメントを使うかで、変異の個数が変わる可能性があって、嬉しくない。
対処としてはいろいろ考えられる。
(1)オーバーラップのあるアラインメント元を結合して、再度マッピングし直す
(2)一意にアラインメントされた連続配列のみを使う
(3)オーバーラップは小さいので、重複カウントを許容する
(1)は、面倒くさいので、今回はpass
(2)をやると、使用できる塩基数は、全体の10〜20%くらいになるようだった。これを使うと、なんか変なbiasが入りそうにも思える。
(3)は、オーバーラップしている配列の長さが、どれくらいあるか見ると、全体の1〜2%程度だったので、(2)よりも、こっちの方がいいかもしれない
とりあえず、(2)と(3)の2つの方法で、変異をカウントすることにした。
第三の問題として、変異として、一塩基置換だけでなく、欠失・挿入(indel)変異が結構ある。非常に長いindel変異があった場合は、単にアラインメントされないだけで済むけど、数bpとか数十bpとかのindelも結構ある。
indel変異が、どうやって生じるのか知らないけど、一塩基置換とは、違う機構で生じてるだろうから、同列に扱って、変異数をカウントするわけにもいかない。どうするのが正解か分からないけど、ここでは、indelの数と一塩基置換の数を別にカウントする。
そんな感じで集計したのが以下の3つの表。チンパンジーとボノボの2番染色体は、2Aと2Bを結合したもの。
項目の内容は、以下の通り。
長さ:種1の染色体の長さ
N以外長:種1の染色体からNを除いた長さ
アライン長:アラインメントされた配列の長さの合計(オーバーラップしてる場合、重複カウントなし)
NA率:1 - アライン長/N以外長
mm数:アラインメントのmismatch数
gap数:アラインメントのgap数
延べアライン長:アラインメントされた配列の長さの合計(オーバーラップしてる場合、重複カウント)
mm率:mm数/延べアライン長
一意mm数:一意にmapされた領域のmismatch数
一意gap数:一意にmapされた領域のgap数
一意アライン長:一意にmapされた領域の長さ合計
一意mm率:一意mm数/一意アライン長
| 種1 | 種2 | 染色体 | 長さ(bp) | N以外長(bp) | アライン長(bp) | NA率(%) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | 一意mm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | 一意mm率(%) |
| hg38 | panPan3 | 1 | 248956422 | 230481012 | 211326047 | 8.31 | 4011423 | 2490943 | 218939691 | 1.83 | 489230 | 327328 | 37384259 | 1.31 |
| hg38 | panPan3 | 2 | 242193529 | 240548228 | 216230598 | 10.11 | 3191827 | 2356796 | 218702748 | 1.46 | 606728 | 392000 | 46921712 | 1.29 |
| hg38 | panPan3 | 3 | 198295559 | 198100135 | 192513270 | 2.82 | 2734338 | 1915719 | 194161004 | 1.41 | 459272 | 290331 | 34845909 | 1.32 |
| hg38 | panPan3 | 4 | 190214555 | 189752667 | 178311882 | 6.03 | 2602568 | 1843202 | 179568850 | 1.45 | 432645 | 271535 | 31295942 | 1.38 |
| hg38 | panPan3 | 5 | 181538259 | 181265378 | 172566849 | 4.80 | 2513031 | 1839739 | 174245507 | 1.44 | 469853 | 305126 | 35746564 | 1.31 |
| hg38 | panPan3 | 6 | 170805979 | 170078522 | 164233097 | 3.44 | 2348255 | 1758045 | 165709615 | 1.42 | 446327 | 298054 | 33412246 | 1.34 |
| hg38 | panPan3 | 7 | 159345973 | 158970131 | 139096154 | 12.50 | 2190826 | 1751305 | 141239753 | 1.55 | 410932 | 276398 | 30816340 | 1.33 |
| hg38 | panPan3 | 8 | 145138636 | 144768136 | 134358784 | 7.19 | 2140239 | 1518162 | 135957257 | 1.57 | 365951 | 220580 | 26724157 | 1.37 |
| hg38 | panPan3 | 9 | 138394717 | 121790550 | 107461797 | 11.77 | 1644566 | 1230962 | 108897061 | 1.51 | 305591 | 191731 | 21337822 | 1.43 |
| hg38 | panPan3 | 10 | 133797422 | 133262962 | 124549728 | 6.54 | 1820572 | 1349855 | 125620922 | 1.45 | 288628 | 188972 | 21262369 | 1.36 |
| hg38 | panPan3 | 11 | 135086622 | 134533742 | 126993565 | 5.60 | 1931728 | 1415019 | 128783087 | 1.50 | 395402 | 254502 | 28504913 | 1.39 |
| hg38 | panPan3 | 12 | 133275309 | 133137816 | 127511615 | 4.23 | 2013237 | 1535997 | 129623090 | 1.55 | 292995 | 198646 | 22584098 | 1.30 |
| hg38 | panPan3 | 13 | 114364328 | 97983125 | 93979048 | 4.09 | 1423431 | 1083806 | 95045780 | 1.50 | 235901 | 154696 | 17526209 | 1.35 |
| hg38 | panPan3 | 14 | 107043718 | 90568149 | 85596710 | 5.49 | 1214793 | 902336 | 86162736 | 1.41 | 185828 | 117081 | 13386909 | 1.39 |
| hg38 | panPan3 | 15 | 101991189 | 84641325 | 74652459 | 11.80 | 1154603 | 862767 | 75716063 | 1.52 | 189245 | 118180 | 13694205 | 1.38 |
| hg38 | panPan3 | 16 | 90338345 | 81805943 | 58332032 | 28.69 | 1072360 | 857620 | 59483550 | 1.80 | 138167 | 92094 | 8829857 | 1.56 |
| hg38 | panPan3 | 17 | 83257441 | 82920204 | 73887034 | 10.89 | 1226625 | 1156821 | 75482801 | 1.63 | 122733 | 89702 | 9334517 | 1.31 |
| hg38 | panPan3 | 18 | 80373285 | 80089605 | 72816500 | 9.08 | 1075197 | 809119 | 73640452 | 1.46 | 192004 | 120683 | 14766732 | 1.30 |
| hg38 | panPan3 | 19 | 58617616 | 58440758 | 52197242 | 10.68 | 1287588 | 1278307 | 54212987 | 2.38 | 113730 | 78528 | 5422289 | 2.10 |
| hg38 | panPan3 | 20 | 64444167 | 63944257 | 57950327 | 9.37 | 923266 | 729540 | 58644249 | 1.57 | 131835 | 86749 | 8961738 | 1.47 |
| hg38 | panPan3 | 21 | 46709983 | 40088619 | 32948983 | 17.81 | 562624 | 476912 | 33358823 | 1.69 | 72473 | 49665 | 4339058 | 1.67 |
| hg38 | panPan3 | 22 | 50818468 | 39159777 | 30341016 | 22.52 | 580286 | 567784 | 31273295 | 1.86 | 59108 | 41820 | 3934839 | 1.50 |
| hg38 | panPan3 | X | 156040895 | 154893029 | 138882071 | 10.34 | 1725370 | 1335905 | 140678371 | 1.23 | 316883 | 220643 | 29799564 | 1.06 |
| hg38 | panPan3 | All | 3031042417 | 2911224070 | 2666736808 | 8.40 | 41388753 | 31066661 | 2705147692 | 1.53 | 6721461 | 4385044 | 500832248 | 1.34 |
| 種1 | 種2 | 染色体 | 長さ(bp) | N以外長(bp) | アライン長(bp) | NA率(%) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | 一意mm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | 一意mm率(%) |
| hg38 | panTro6 | 1 | 248956422 | 230481012 | 215833532 | 6.36 | 3202777 | 2340222 | 218834662 | 1.46 | 488415 | 323251 | 38379383 | 1.27 |
| hg38 | panTro6 | 2 | 242193529 | 240548228 | 228187989 | 5.14 | 3325430 | 2401774 | 230629960 | 1.44 | 549332 | 350165 | 42362608 | 1.30 |
| hg38 | panTro6 | 3 | 198295559 | 198100135 | 192455019 | 2.85 | 2737275 | 1901600 | 194174363 | 1.41 | 476359 | 302644 | 36248026 | 1.31 |
| hg38 | panTro6 | 4 | 190214555 | 189752667 | 179552479 | 5.38 | 2614502 | 1807970 | 180753955 | 1.45 | 450252 | 294916 | 31780919 | 1.42 |
| hg38 | panTro6 | 5 | 181538259 | 181265378 | 155687512 | 14.11 | 2260392 | 1644746 | 157149191 | 1.44 | 395220 | 250928 | 29926537 | 1.32 |
| hg38 | panTro6 | 6 | 170805979 | 170078522 | 164878095 | 3.06 | 2316294 | 1707706 | 166067400 | 1.39 | 432293 | 286325 | 33170628 | 1.30 |
| hg38 | panTro6 | 7 | 159345973 | 158970131 | 145995918 | 8.16 | 2323815 | 1912622 | 148463967 | 1.57 | 357182 | 234234 | 26537796 | 1.35 |
| hg38 | panTro6 | 8 | 145138636 | 144768136 | 138870391 | 4.07 | 2238209 | 1565088 | 140704853 | 1.59 | 342273 | 205295 | 24943797 | 1.37 |
| hg38 | panTro6 | 9 | 138394717 | 121790550 | 108265834 | 11.10 | 1655840 | 1233137 | 109537762 | 1.51 | 296335 | 183730 | 20749369 | 1.43 |
| hg38 | panTro6 | 10 | 133797422 | 133262962 | 125735092 | 5.65 | 1879342 | 1441851 | 127223721 | 1.48 | 255187 | 162895 | 19738611 | 1.29 |
| hg38 | panTro6 | 11 | 135086622 | 134533742 | 127793622 | 5.01 | 1996211 | 1446584 | 129954022 | 1.54 | 342653 | 212423 | 22548279 | 1.52 |
| hg38 | panTro6 | 12 | 133275309 | 133137816 | 127583029 | 4.17 | 2013686 | 1566677 | 129715958 | 1.55 | 239415 | 164539 | 18981808 | 1.26 |
| hg38 | panTro6 | 13 | 114364328 | 97983125 | 92823728 | 5.27 | 1413254 | 1088623 | 94008472 | 1.50 | 222636 | 145908 | 16739471 | 1.33 |
| hg38 | panTro6 | 14 | 107043718 | 90568149 | 85881820 | 5.17 | 1241760 | 944185 | 86727424 | 1.43 | 191949 | 126862 | 14477916 | 1.33 |
| hg38 | panTro6 | 15 | 101991189 | 84641325 | 74907636 | 11.50 | 1102410 | 809997 | 75473089 | 1.46 | 206258 | 134672 | 15211413 | 1.36 |
| hg38 | panTro6 | 16 | 90338345 | 81805943 | 69133372 | 15.49 | 4264843 | 3162593 | 85151336 | 5.01 | 195438 | 125850 | 13101659 | 1.49 |
| hg38 | panTro6 | 17 | 83257441 | 82920204 | 71026365 | 14.34 | 1174975 | 1094492 | 72624100 | 1.62 | 129927 | 96927 | 9896992 | 1.31 |
| hg38 | panTro6 | 18 | 80373285 | 80089605 | 73276926 | 8.51 | 1081080 | 819001 | 74084370 | 1.46 | 168131 | 104444 | 12671686 | 1.33 |
| hg38 | panTro6 | 19 | 58617616 | 58440758 | 52454285 | 10.24 | 1522710 | 1432471 | 55626497 | 2.74 | 69999 | 56400 | 3469737 | 2.02 |
| hg38 | panTro6 | 20 | 64444167 | 63944257 | 58982787 | 7.76 | 997655 | 812384 | 60110754 | 1.66 | 117187 | 81681 | 7931760 | 1.48 |
| hg38 | panTro6 | 21 | 46709983 | 40088619 | 32938437 | 17.84 | 564768 | 483475 | 33406289 | 1.69 | 100002 | 69666 | 6680505 | 1.50 |
| hg38 | panTro6 | 22 | 50818468 | 39159777 | 32591471 | 16.77 | 634735 | 621430 | 33616521 | 1.89 | 56852 | 43958 | 3445051 | 1.65 |
| hg38 | panTro6 | X | 156040895 | 154893029 | 143952140 | 7.06 | 1771650 | 1467389 | 145587312 | 1.22 | 351165 | 242928 | 32901624 | 1.07 |
| hg38 | panTro6 | All | 3031042417 | 2911224070 | 2698807479 | 7.30 | 44333613 | 33706017 | 2749625978 | 1.61 | 6434460 | 4200641 | 481895575 | 1.34 |
| 種1 | 種2 | 染色体 | 長さ(bp) | N以外長(bp) | アライン長(bp) | NA率(%) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | 一意mm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | 一意mm率(%) |
| panPan3 | panTro6 | 1 | 224621958 | 220997261 | 211408421 | 4.34 | 1242852 | 1223351 | 214165393 | 0.58 | 247715 | 215892 | 57048896 | 0.43 |
| panPan3 | panTro6 | 2 | 234328823 | 232081668 | 221068373 | 4.75 | 1174894 | 1131774 | 222935250 | 0.53 | 244639 | 207520 | 56180170 | 0.44 |
| panPan3 | panTro6 | 3 | 195577393 | 195047306 | 193641211 | 0.72 | 988899 | 918601 | 195204995 | 0.51 | 198744 | 161942 | 45762412 | 0.43 |
| panPan3 | panTro6 | 4 | 182437434 | 181719665 | 179826027 | 1.04 | 966998 | 940551 | 181370766 | 0.53 | 243455 | 197249 | 56676707 | 0.43 |
| panPan3 | panTro6 | 5 | 176502593 | 175897314 | 157332894 | 10.55 | 818305 | 789075 | 158740747 | 0.52 | 183147 | 149644 | 41996818 | 0.44 |
| panPan3 | panTro6 | 6 | 168932342 | 167194355 | 165212354 | 1.19 | 1128505 | 952755 | 168097063 | 0.67 | 215167 | 172122 | 46373059 | 0.46 |
| panPan3 | panTro6 | 7 | 150536359 | 148119694 | 144148669 | 2.68 | 1015752 | 1045487 | 146732140 | 0.69 | 146631 | 127817 | 31155278 | 0.47 |
| panPan3 | panTro6 | 8 | 141842281 | 140480805 | 135782485 | 3.34 | 1115386 | 1135376 | 139867990 | 0.80 | 167380 | 135248 | 35673626 | 0.47 |
| panPan3 | panTro6 | 9 | 109767803 | 109102898 | 107466461 | 1.50 | 698559 | 644809 | 109265604 | 0.64 | 108252 | 86810 | 25132551 | 0.43 |
| panPan3 | panTro6 | 10 | 128853861 | 127403410 | 125455656 | 1.53 | 712645 | 711007 | 126726439 | 0.56 | 125168 | 104413 | 28882031 | 0.43 |
| panPan3 | panTro6 | 11 | 129867894 | 128778196 | 127836374 | 0.73 | 777013 | 737757 | 130017666 | 0.60 | 126076 | 100038 | 29767584 | 0.42 |
| panPan3 | panTro6 | 12 | 131319602 | 130620582 | 128842824 | 1.36 | 869906 | 853405 | 130936288 | 0.66 | 99972 | 86042 | 22909330 | 0.44 |
| panPan3 | panTro6 | 13 | 95736914 | 95347524 | 94636041 | 0.75 | 602614 | 635899 | 96078485 | 0.63 | 98474 | 79991 | 22727732 | 0.43 |
| panPan3 | panTro6 | 14 | 87894197 | 87229111 | 86107277 | 1.29 | 480703 | 470890 | 86828669 | 0.55 | 117367 | 101607 | 26751421 | 0.44 |
| panPan3 | panTro6 | 15 | 80799215 | 77887030 | 76499433 | 1.78 | 589840 | 580985 | 78734716 | 0.75 | 86680 | 76662 | 19255098 | 0.45 |
| panPan3 | panTro6 | 16 | 71000456 | 68862913 | 65288186 | 5.19 | 529206 | 562812 | 66784252 | 0.79 | 63103 | 58611 | 13190471 | 0.48 |
| panPan3 | panTro6 | 17 | 77747126 | 76408544 | 71450496 | 6.49 | 558443 | 690618 | 73637454 | 0.76 | 49753 | 49783 | 10307593 | 0.48 |
| panPan3 | panTro6 | 18 | 74093087 | 73811721 | 73319584 | 0.67 | 427623 | 431573 | 74307311 | 0.58 | 67895 | 54653 | 15603773 | 0.44 |
| panPan3 | panTro6 | 19 | 55604062 | 54161911 | 51332629 | 5.22 | 725355 | 704605 | 53560123 | 1.35 | 18966 | 21133 | 2851849 | 0.67 |
| panPan3 | panTro6 | 20 | 59769695 | 59326525 | 58701181 | 1.05 | 420088 | 462338 | 59851436 | 0.70 | 51222 | 45986 | 11314431 | 0.45 |
| panPan3 | panTro6 | 21 | 33144400 | 32979067 | 32656727 | 0.98 | 349002 | 356870 | 34092161 | 1.02 | 30791 | 26047 | 6226697 | 0.49 |
| panPan3 | panTro6 | 22 | 31064846 | 30827669 | 30369603 | 1.49 | 269873 | 332729 | 31369400 | 0.86 | 17707 | 21580 | 3453695 | 0.51 |
| panPan3 | panTro6 | X | 146233785 | 142690712 | 138587829 | 2.88 | 623812 | 689899 | 139844759 | 0.45 | 143017 | 133816 | 42843965 | 0.33 |
| panPan3 | panTro6 | All | 2787676126 | 2756975881 | 2676970735 | 2.90 | 17086273 | 17003166 | 2719149107 | 0.63 | 2851321 | 2414606 | 652085187 | 0.44 |
一応、同一種で異なるバージョンのゲノム配列を比較すると、どうなるのかという結果も示しておく。ヒト同士、チンパンジー同士でも、当然、個体差はあるが、以下の結果にある差が、何に起因してるものかは知らない。
| 配列1 | 配列2 | 染色体 | 長さ(bp) | N以外長(bp) | アライン長(bp) | NA率(%) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | 一意mm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | 一意mm率(%) |
| hg19 | hg38 | All | 3036303846 | 2835673565 | 2822164041 | 0.48 | 2492583 | 2055392 | 2852841368 | 0.09 | 54529 | 54025 | 1189501531 | 0.00 |
| panTro3 | panTro6 | All | 3120320700 | 2730903704 | 2639535394 | 3.35 | 5905860 | 11426105 | 2658755472 | 0.22 | 2919588 | 6947610 | 2212217864 | 0.13 |
ヒトvsチンパンジー、ヒトvsボノボは、よく似た結果となってる。ボノボとチンパンジーが似てるので、当然だけど。
X染色体のミスマッチ率はやや低く、X染色体は変異が少ないという一般的な報告と一致している。19番染色体は、どの組み合わせでも、変異が多いように見える。これは、本当に、変異が多かったり少なかったりしてるのか、よく分からない。19番染色体は、hg19:hg38やpanTro3:panTro6の比較でも、ミスマッチ率が高い。
ミスマッチ数は、チンパンジーvsボノボと、ヒトvsチンパンジーでは、2.5倍弱の違いがある。時間経過と共に、NA率やミスマッチ数が一定率で増えていくとすれば、分岐時期が、その程度違うのだと考えられる。TIMETREEによると、複数の研究の予測分岐年代の中央値が、240万年と640万年で、比率は2.67だから、これらが概ね正解の可能性もある。
分子時計では、相同率が小さい場合は、多重置換(同じ箇所で複数回の置換が起こること)や復帰置換(同じ箇所で2回以上の置換が起こって、元の塩基に戻ること)によって、ミスマッチ数と分岐時期が比例するとは考えられなくなる。ヒトとチンパンジー・ボノボは、十分似てるので、このような影響は小さく、無視して差し支えないと思われる。
一般的に、ヒトとチンパンジーのゲノムは98%以上似ているとか聞くけど、確かにアラインメントされた領域での一致率は、それくらいある。一方で、アラインメントされてない領域が8%くらいある。hg38とpanTro6,panPan3では、そもそも、配列の全長が7〜8%ほど違うので、この差は、むしろ当然にも思える。ただ、この領域が、何なのかは気になる。
大きなNA率を持つ染色体をいくつか確認すると、16番染色体は、中央付近の16p11.1、16q11.1、16q11.2付近の領域が、ヒト固有らしいけど、アノテーションされてる遺伝子が全然ない空白地帯になってる。
Chr16:1-90.34M
https://www.ncbi.nlm.nih.gov/genome/gdv/browser/?context=genome&acc=GCF_000001405.39&chr=16
この付近に相当する領域が、他の類人猿にないのは確からしいが、ヒトでは、Nになってて配列が決定されてない部分も多くて、アノテーションできてないだけかもしれない。大体、8.5(Mb)程度は、Nになってて、この付近20(Mb)近くに及ぶ配列の相同領域が、チンパンジーやボノボで確認できない。9番染色体のセントロメア付近にも同じような領域がある。
他に、13,14,15,21,22番染色体のp-arm端っこに似たような領域がある。これらは、アクロセントリック染色体というカテゴリーに分類され、Robertson型転座を起こすことで知られる。Robertson型転座の一般的説明では、これらの短椀がなくなっても、表現型は正常とされる。多分、これが根拠で、アクロセントリック染色体の短椀には、遺伝子が載ってないとか、重要な遺伝子がないとされている。
配列が決定されてない割合が高くて、アノテーションされた遺伝子もないけど、例外的に、21p12は、遺伝子がアノテーションされてる。これは、何らかの予測アルゴリズムによって、遺伝子コーディング領域と判定されただけのようで、本当に、遺伝子をコードしてるのかは分からない。
Chr21:1-46.71M
https://www.ncbi.nlm.nih.gov/genome/gdv/browser/genome/?id=GCF_000001405.39&chr=21
21番染色体のこの領域に相同な領域は、チンパンジー・ボノボの他の染色体上にも見つからなかったので、どこから来たのか謎。ゴリラにもないので、ヒトとチンパンジー・ボノボの系統が分岐した後、チンパンジー・ボノボが、これに相当する領域を失ったというわけでもなさそう。
とりあえず、全体として、200〜300(Mb)ほど、ヒト固有配列が存在してるように見える。今の所、これらの領域が特に重要だと考える理由はないっぽい。
そういうのとは別に、他の種では保存されてるのに、ヒトだけ変化が著しいhuman accelerated regionsというのも知られている。それが重要なのかは知らない。
TIMETREEに載ってる結果は、分子時計によるものだけど、分子進化速度一定という条件だけでは、分岐時期の相対年代しか決まらない。絶対年代を決めるために、化石年代に基づくcalibrationを利用してるのが普通じゃないかと思う。calibrationに使う基準年代は恣意的で、正しい方法とかはない。よく使われる標準的な年代はいくつかあるけど、それが正しくないと、多くの結果が共倒れになる。一方、仮に、分子進化の速度が一定なら、現代で、直接、変異率を測定してもいいはず。絶対的な分子進化の速度が測定できれば、化石年代に依存しない分岐時期推定ができるようになるはず。
一世代で、どれくらい新しくSNV(single nucleotide variant)が増えるか、理論的に知ることは難しいと思う。DNAポリメラーゼが、どれくらい複製ミスを起こすか程度なら、もしかしたら見積もれるかもしれない。細菌でも、複製ミスの校正機構があるので、実際のSNV獲得速度の予測は難しくなる。哺乳類とかになると、生殖細胞の分裂速度も種によって違うだろうが、何で決まってるのか分からない。
SNV増加速度が、種の存続を維持できる限界になっているみたいな条件(つまり、高すぎる変異率は有害変異増大のリスクがあり、低すぎる変異率は環境適応力低下のリスクがあるので、どっちかのリスクが、限界スレスレになるような変異率になってるかもしれない)が成立している可能性もあるけど、定かではないし、そういう観点から変異率を決定するのも難しそう。
なので、一世代で、どれくらいSNVが増えるか、実験的に調べるしかない。2010年頃から、こういう検証が可能になって、いくつか報告が出ている。
Fathers bequeath more mutations as they age
https://doi.org/10.1038/488439a
Rate of de novo mutations and the importance of father’s age to disease risk
https://doi.org/10.1038/nature11396
Similarities and differences in patterns of germline mutation between mice and humans
https://www.nature.com/articles/s41467-019-12023-w
"変異"/mutationと書いてるが、点変異以外に、挿入、欠失なども変異ではあるので、SNVという方が適切に思う。
最初の論文には、父親(の生殖細胞)から受け継がれる変異の方が多く、(現代では)平均して、父親から55個、母親から14個の変異(合計69個)を受け継いでて、また、父親の年齢が高いと、変異が急速に増えるとも書いてる。
2番目の論文には、父親の年齢と新生児の変異数のグラフが載ってて、"The number of mutations increases with father’s age with an estimated effect of 2.01 mutations per year"とある。
3番目の論文は、数字だけほしいなら、TABLE1を見るのがいいと思う。ヒトでは、世代あたりの新規変異数は、平均71個。" Mutation rate per genome per generation"は、1.22e-8となっている。ヒトゲノム配列の決定された長さが29.1e8(bp)で、染色体は2本ずつあるので、71/29.1e8/2=1.22e-8ってことだろう。一世代30年として計算された"Mutation rate per year"は、4.08e-10で、一年で平均2〜3個変異が増えるのに相当。
ついでに、マウスは、ヒトより大分変異が入る頻度が高いらしい。一世代で20個となっていて、マウスの一世代は3ヶ月とか言われるが、ここでは、一世代9ヶ月を仮定したと書いてある(マウスの飼育をしたことがないので、実際の感覚としてどうなのか分からないが)。それでも、ヒトの10倍くらいの速度で新規SNVを獲得していく見積もりになる。
進化的に遠い動物を見ると、ショウジョウバエの変異率の報告が2007年の論文に出ていて、Abstractには、変異率は、8.4e-9(/site/generation)だと書いてある。
Direct estimation of per nucleotide and genomic deleterious mutation rates in Drosophila
https://doi.org/10.1038/nature05388
ショウジョウバエのゲノムサイズは、200(Mb)程度で、染色体は2本ずつあるので、一世代当たり3個くらい変異が入る計算。ショウジョウバエは、実験室では、最大2ヶ月ほど生きるが、ここでの一世代が何を指してるのかは定かでない。一世代1.5ヶ月とすれば、ショウジョウバエのSNV獲得速度は、年間25個くらいだろう。マウスと大差ないってことになるけど、本当か?
以下、数百万年程度の短期間では、同じ箇所に変異が入るケースは十分少ないと考える。つまり、ある塩基配列に頻度αでランダムに置換が入った2つの配列を比較した場合、同一箇所に同じ変異が入る可能性もあるので、ミスマッチ率の期待値はとなるが、αが小さければ、第二項は無視できる。また、点置換は、過去に一度起こった箇所に再度起こる可能性もあって、αは世代数や経過時間に厳密に比例するわけではないけど、その影響も無視する。
ヒトの世代あたりの新規変異数が、上の論文にある通り、平均71個で、一世代30年とすると、年平均2.4個程度の新規SNV獲得がある。そうして仮に、ヒトとチンパンジー・ボノボで、SNVが同程度の頻度で増えるなら、ミスマッチ数は、ゲノム全長は30億bpとして(染色体は2本あって、片方だけ見ると変異の数は半分になるので)年平均2.4bp/yearくらいで増加していくだろう。現在のミスマッチ数が、30億bpの1.5%と考えると、このミスマッチ数に到達するまで、約1900万年かかるという計算になる。つまり、ヒトとチンパンジー・ボノボの分岐年代が、そのあたりということ。これは、一世代30年に基づく計算なので、かなりざっくりしてはいる。仮に、一世代20年で、世代あたり変異数が71個だとすれば、分岐年代は、約1300万年前になる。
大分、単純な算数だけど、難しいモデルを使って得られる見積もりが信用できるかも分からない。それとは別に気になるのは、SNV検出の信頼性で、解析の方法を見る限り、取りこぼしたSNVがないか分からない。ただ、生データもないし、これに関しては、書いてることを信用するしかない。
また、これらは現代のデータであって、現代のヒトの生活は、野生とは大きく異なってるので、そのまま過去の数百万年に適用していいかも疑問がある。それに、マウスとヒトでは、SNV増加速度が大きく異なってるので、ヒトとチンパンジー・ボノボのSNV増加速度が、同程度かどうかも検証されるべきである。けど、チンパンジーやボノボの計測は少ない。
チンパンジーで、一世代で生じる新規SNVを調べた最初の論文は、2014年のものだと思う。
Strong male bias drives germline mutation in chimpanzees
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4746749/
が、その論文で、変異率は、ヒトと、あまり変わらないと報告している。父親の年齢と変異数のグラフFig3(B)にある通り、ヒト同様、父親の年齢増加と共に、変異数も増加するらしい。父親の年齢増加による影響が、ヒトより大きいとも書いてるけど、標本数が少ないので、言い切るには根拠が弱い気もする。
チンパンジーも飼育下にあるものなので、野生なら違う数字が出るとかいう可能性もなくはない。この論文では、一世代で平均35の新規変異が検出できたが、そもそも、チンパンジーの生殖年齢が野生より若く、実験で使用できた常染色体の長さが、2360Mbだったことなどから、野生下では、もう少し多くの変異が入ると考えているらしい。
論文では、変異率を1.2e-8/bp/generationと書いてる。単位が"per basepair per generation"って分かりにくいと思うけど、1.2e-8/site/generationと同じ意味と思われる。野生チンパンジーの父母の平気年齢が、24.3歳と26.3歳なので、一世代の長さは25年くらいで、一年あたりの変異率は、4.8e-10(/site/year)くらいとなる。論文では、4.6e-10(/site/year)とかいう数字が出ているから、こっちを使おう。ヒトとチンパンジーの変異速度が、こんなものであれば、(ゲノム全長は30億bpとして)ミスマッチ数は、2.76bp/year程度の速度で増加する。
論文では、ヒトとチンパンジーの常染色体のdivesityを1.2%と計測してる(私は、X染色体も含めて1.6%くらいになってるけど、使用配列や条件が違うせいだろう)ので、ヒトとチンパンジーの分岐年代は1300万年前と見積もられている。diversityが、1.5%くらいなら、分岐時期は1630万年前となる。
2017年には、
京都大学霊長類研究所チンパンジー・アイ
https://www.pri.kyoto-u.ac.jp/sections/langint/ai/ja/friends/akira.html
らを対象とした計測がなされたらしい。
Direct estimation of de novo mutation rates in a chimpanzee parent-offspring trio by ultra-deep whole genome sequencing
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5666008/
が論文で、一年あたりの変異率は、6.2e-10(/site/year)とされている。標本数は少ないが、coverageが高い。ミスマッチ数増加速度にすると、3.72bp/yearで、ヒトとチンパンジーのdiversityが1.5%なら、分岐時期は1200万年前。子供は、父母が24歳の時に生まれたらしく、ターゲットになってるゲノム領域のサイズの違いを勘案すれば、得られた結果は、既に言及した2014年の報告と大きな齟齬はないと思う。
チンパンジー親子トリオ全ゲノム解析による世代間直接変異率の推定
https://doi.org/10.14907/primate.30.0_46_2
は論文に先立ってなされた学会発表じゃないかと思うけど、この時は、"2x10−8/site/generation という変異率の結果を得た"と書いてあって、論文では、1.48e-8(/site/generation)に下方修正されてる。
ともかく現時点では、直接測定した変異率から算出されるヒトとチンパンジーの分岐時期は、いくつかの要因で大きめの誤差が出るものの、見つかってる化石から予想されている時期と比べると、2倍程度の差があるということになる。
古生物学者がどういう基準で種の区別をしてるのか何も知らないけど、遺伝型の分岐が始まっても、すぐに別種になるわけではない。例えば、地理的隔離が起きて、2つの集団が交流できない状態に置かれた場合、隔離された時点で分岐は始まるけど、暫く(多分、数十万年〜数百万年)の間は、別種か亜種か曖昧な状態にある。なので、分子生物学に基づく分岐時期の方が古くなるのは意外ではない。それでも、2倍近い開きは、ちょっと許容し難い気もする。
明確に、形態的な差が見られるまで、どのくらい時間がかかるのかは、何とも言えない。数百万年単位の時間になる場合もあるなら、この食い違いは矛盾ではないのかもしれない。だとすると、人類誕生の瞬間とかいうのが、点推定できるとか、せいぜい幅10万年くらいの幅で区間推定できるという考えの方が間違ってるってことかもしれない。
別の可能性として、ヒトやチンパンジーのSNV獲得速度が、昔は、もっと早かったということも考えられる。昔のSNV獲得速度を直接測定することはできないけど、チンパンジーとボノボの平均的なSNV獲得速度が同程度だっただろうことは、ヒトvsチンパンジー、ヒトvsボノボで、ミスマッチ数が、あんまり変わらないことが、一つの証拠になると思う。
同様に、過去に、ヒトとチンパンジー・ボノボで、平均的なSNV増加速度が大きく違っていたかどうかは、ゴリラvsヒト、ゴリラvsチンパンジー、ゴリラvsボノボで、ゲノム配列の比較をして、ミスマッチ数が同程度であるかどうかを見ればいいと思われる。ヒトのSNV増加がチンパンジーやボノボより遅いのであれば、ゴリラvsヒトでのミスマッチ数は、ゴリラvsチンパンジーのそれより少なくなるだろう。
それを、ヒトvsチンパンジー、ヒトvsボノボなどと同様にして、集計したのが以下の表。全ての染色体を総合した値だけ記載しておく。ゴリラの染色体再編成に気付いてなかったので、微妙に正しくないけど、ミスマッチ率に大きな影響はないと思う。
| 種1 | 種2 | 染色体 | 長さ(bp) | N以外長(bp) | アライン長(bp) | NA率(%) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | 一意mm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | 一意mm率(%) |
| hg38 | gorGor6 | All(誤) | 3031042417 | 2911224070 | 2505541453 | 13.94 | 46389396 | 32032823 | 2529294557 | 1.83 | 8388576 | 5095767 | 488943692 | 1.72 |
| panTro6 | gorGor6 | All(誤) | 2806264745 | 2778203836 | 2458126908 | 11.52 | 45581086 | 29988783 | 2480919890 | 1.84 | 9303630 | 5366060 | 543123352 | 1.71 |
| panPan3 | gorGor6 | All(誤) | 2787676126 | 2756975881 | 2411986204 | 12.51 | 44802651 | 29484228 | 2435742153 | 1.84 | 8990493 | 5185914 | 525940481 | 1.71 |
ミスマッチ率に殆ど差がないので、おそらく、ヒト、チンパンジー、ボノボのSNVは、ほぼ同じ割合で増えてきたと考えられる。この割合が大きく変動して、たまたま、同程度のミスマッチ率になっているという可能性もなくはないけど、新規SNVの出現頻度は比較的安定していて、同程度のミスマッチ率になっていると考える方が自然に思われる。
ゴリラのSNV増加速度が、ヒト・チンパンジー・ボノボと同程度かは再び分からないが、それを知りたければ、今度は、オランウータンvsヒト、オランウータンvsゴリラなどでミスマッチ率を比較すればいいはず。
Revising the human mutation rate: implications for understanding human evolution
https://doi.org/10.1038/nrg3295
のFigure1を見ると、ゴリラ、チンパンジーの変異率は同程度だが、オランウータンやアカゲザルなどは、それより少し高頻度だと書いてある。
ヒト、ゴリラ、チンパンジー、ボノボとオランウータンのゲノム比較情報を集計してみると、以下のようになっていた。
| 種1 | 種2 | 染色体 | 長さ(bp) | N以外長(bp) | アライン長(bp) | NA率(%) | mm数(bp) | gap数(bp) | 延べアライン長(bp) | mm率(%) | 一意mm数(bp) | 一意gap数(bp) | 一意アライン長(bp) | 一意mm率(%) |
| hg38 | ponAbe3 | All | 3031042417 | 2911224070 | 2571366884 | 11.67 | 92428393 | 57288976 | 2608437771 | 3.54 | 15188373 | 8240948 | 456454886 | 3.33 |
| gorGor6 | ponAbe3 | All(誤) | 2757155739 | 2715359355 | 2369321035 | 12.74 | 84650232 | 49597010 | 2397492689 | 3.53 | 15192869 | 7948024 | 453217728 | 3.35 |
| panTro6 | ponAbe3 | All | 2806264745 | 2778203836 | 2496060105 | 10.16 | 89839276 | 54030407 | 2531232513 | 3.55 | 15402587 | 8189403 | 461144924 | 3.34 |
| panPan3 | ponAbe3 | All | 2787676126 | 2756975881 | 2480799795 | 10.02 | 89115234 | 53403694 | 2515549386 | 3.54 | 15563149 | 8267168 | 465299818 | 3.34 |
なんかミスったか心配になる程度に、ミスマッチ率が近い。染色体ごとに見ると、結構違いがあるけど、平均化すると、ほぼ同じ感じになる。ヒトとゴリラが分岐して結構経つのに、これくらい近い数字が出るということは、新規SNV出現頻度は、ヒトとチンパンジーが分岐する以前から、安定していたと考えるのが、自然に思える。過去に、ヒトのSNV獲得頻度の変動があったとすれば、チンパンジー、ボノボ、ゴリラなどでも、共通の影響を受けた可能性が高い。そのような変動があったとしても、この表からは、何の情報も引き出せない。
ヒトvsオランウータン、ゴリラvsオランウータンのmm率は、ヒトvsチンパンジーやヒトvsボノボの2.5倍弱。SNV獲得速度が、ヒトとオランウータンの系統で、ずっと一定だったなら、ヒト・オランウータン分岐年代と、ヒト・チンパンジーの分岐年代の比は、2.5倍程度になるはず。つまり、ヒト・チンパンジーの分岐が600万年前なら、ヒト・オランウータンの分岐は1300〜1500万年前とかいう計算になる。
SNV獲得速度が、ヒトとオランウータンで違うなら、この見積もりは妥当でなくなる。それを見るには、大型類人猿と近縁なテナガザルとの比較を見るというのが自然な流れだけど、テナガザルは、染色体数が大型類人猿と異なり、ゲノム配列も割とシャッフルされてるらしいので、ゲノム全体の比較も、大型類人猿同士の時より少し面倒になる。アカゲザルなんかの方が、むしろ対応関係は単純で、そっちを使えばいいかもしれないけど、それでも、大型類人猿のように、単純な1:1対応は作れないので、一旦、ここで打ち止め。
チンパンジー、ゴリラ、オランウータンの実物すら見たことないけど、若干の疑問はあるとはいえ、とりあえず、大型類人猿の系統関係が確認できてよかった。
話が逸れるけど、増殖のたびに変異が入るのは、生殖細胞以外の体細胞も同様である。生殖細胞以外での変異率は、どうなってるのか気になる。組織ごとに、幹細胞に入る点突然変異の数を調べた論文が、2016年に出ている。
Tissue-specific mutation accumulation in human adult stem cells during life
https://doi.org/10.1038/nature19768
途中までしか読んでないけど、Figure1を見る限り、結腸、小腸、肝臓について、それぞれ10〜20人程度の比較を行っていると思われる。結論は単純で、組織や年齢によらず、平均して、年間40個程度の変異が入るとしている。ヒト生殖細胞の変異が2〜3個/年だったのと比べると、相当に多い可能性がある。教科書的には、肝臓細胞は、年に一回程度分裂するらしい(大部分の時間は、G0期で細胞周期は停止している、とされている)。そうすると、肝臓では、一回の複製で、40個ほどコピーミスがあるということかもしれない。
Somatic mutagenesis in satellite cells associates with human skeletal muscle aging
https://doi.org/10.1038/s41467-018-03244-6
は、2018年の論文で、21〜78歳のヒトの骨格筋の幹細胞であるサテライト細胞に蓄積しているSNVを調べたらしい。Abstractしか見てないけど、高齢者の方が、変異が多く、変異の蓄積は、平均して13個/年だと書いてある。
40とは結構差があるけど、骨格筋はトレーニングによって増殖したりするわけだし、ゲノム複製一回あたりの変異の数がどうなってるかは分からない。
Clonal dynamics of haematopoiesis across the human lifespan
https://doi.org/10.1038/s41586-022-04786-y
は2022年出版で、主題は変異数を数えることではないけど、Abstractには、造血幹細胞ゲノムに、年平均17個の変異が入るとか書いてある。
組織ごとの細胞増殖速度とかは、よく分からないが、多くの組織で細胞分裂回数の目安としてテロメア長を使うことができる。テロメア長が年齢と共にどう変化するかは、多くの組織で測定されてる。例えば、2005年の総説
テロメア変化から老化を探る
https://www.jstage.jst.go.jp/article/faruawpsj/41/10/41_KJ00009718493/_article/-char/ja
の表1に、多くの測定値が載っている。これによると、肝臓では、年平均55,60,120bp短くなるという3つの報告があるらしい。テロメア長が一回の複製で50〜100bpくらい短くなってるという話を考えると、肝臓細胞が年に一回程度分裂するというのと整合的ではある。
Telomeres shorten at equivalent rates in somatic tissues of adults
https://doi.org/10.1038/ncomms2602
は、2013年の論文で、白血球、筋肉、皮膚、脂肪組織のデータがあり(Figure1)、一次関数でフィッティングすると、いずれの組織も、年平均でおよそ25bpずつ短くなってるらしい。測定は、TRF(telomere restriction fragment)法と呼ばれる古典的な方法による。上総説には、皮膚表皮で36bp/yrという数値が見られる。小腸および大腸粘膜は42bp/yrとなっている。測定データの精度が低くて、確定的なことは言えないけど、肝臓や小腸に見られる変異蓄積の多さは、分裂の頻度が高いことで説明できるのかもしれない。
元の話に戻る。上記の分岐年代推定は、一塩基置換に注目して算出している。それはそれでいいけど、ヒトと類人猿のゲノムを比較すると、それ以外の理由による変化も大きい。
ゲノムが変化する要因には、レトロトランスポゾンの転移や挿入、それからsegmental dupliactionなどが考えられている。segmental duplicationは、遺伝子重複を起こす場合がある。最近は、遺伝子重複やコピー数多型が、意外と沢山あることが示されつつある。ヒトの重複遺伝子の中には、ヒトとチンパンジー・ボノボが分岐した後に生じた(と思われる)ものも見つかってる。これらの遺伝子は、パラログとはいえ、ヒト固有の遺伝子ということになる。
ヒトのゲノム配列から、このような新規重複遺伝子の候補は列挙できると思うけど、現時点で、実際に発現しているかどうか確認されてるのは、ごく少数だと思う。見かけ上、沢山あるけど、実際に機能してるのは、10個くらいだったとかいうことも、今の所は、ありえるかもしれない。
Lineage-Specific Gene Duplication and Loss in Human and Great Ape Evolution
https://doi.org/10.1371/journal.pbio.0020207
は2004年の論文で、このような可能性を網羅的に検証しようとした初期のものだと思う。
以下の論文は、一部の遺伝子(全遺伝子の10%程度)は、ヒト同士であっても、コピー数バリアント(多型は、人口の1%以上に存在しないとダメとかいう定義があるけど、コピー数多型と同じようなもの)が見られるということが書いてある(後者の論文のFig3Bなども参照)
Diversity of human copy number variation and multicopy genes
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3020103/
ヒト固有の重複遺伝子で、よく調べられてるのは、神経系に影響する可能性のあるものが主っぽい。ARHGAP11Aの重複遺伝子ARHGAP11B、SRGAP2の重複遺伝子(SRGAP2B,SRGAP2C,SRGAP2Dなどと名付けられている)などは、神経系で何らかの働きをするらしい。これらのコピー数は、ヒトでも、個人差がある。
他に、Notch2NL遺伝子のコピー(Notch2NLA,Notch2NLB,Notch2NLC,Notch2NLR)は、ヒトの脳の容量増大に寄与したという仮説がある
Human-Specific NOTCH2NL Genes Affect Notch Signaling and Cortical Neurogenesis
https://doi.org/10.1016/j.cell.2018.03.051
Notch2NL遺伝子群も、コピー数が人によって違うらしく、Notch2NLRは、1コピーも持たない人が、14%いると書いてある(どういう母集団か確認してない)。Notch2NL遺伝子群は、ヒト、チンパンジー、ボノボ、ゴリラの共通祖先で、Notch2遺伝子の部分重複で生じ、チンパンジーやゴリラでは、偽遺伝子化してるが、ヒトでは、機能を持った遺伝子として働いてるらしい。
重複領域を、機械的に抽出できるか、実験しようと思って、試しに
lastz hg38/chr1.fa hg38/chr1.fa --chain --gfextend --gapped --step=20 --format=maf > hg38_vs_hg38_chr1.maf
とかやって、異なる領域に、アラインされたものを確認すると、1番染色体では、86対の相同性の高いセグメントが見つかった。100bpに満たない短い領域もあるけど、半分くらいは、100〜10000bpの範囲にあり、長い場合は、10万bp以上というのもある。
panTro6やponAbe3の1番染色体で、同じことをやると、hg38の場合と同程度の個数の相同領域対が見つかったが、10万bpを超えるものはなかった。これが、LASTZの問題なのか、ゲノム配列の質の問題なのか、実際に、ヒトでのみ、長い領域の重複が起きたのかは分からない。
hg38では、10万bp以上の相同領域が9対見つかり、25万bpを超える対も2つある(但し、これらは、ほぼ同一の場所なので、実質的には一対)けど、hg19でやった場合は、10万bpを超えるのは2対のみで、最も長い領域で12.5万bp程度。
ここに書いた方法で検出できた(一番染色体上の)相同領域の長さは、(コピー元とコピー先を合わせて)延べ4700kbp弱だった(ほとんど重なってる領域もあるけど、何も考えずに足してる)。これらの重複領域は、別に、ヒト固有のものとは限らないので、ヒト固有の重複領域かどうかは、別途確認していく必要がある。
ここでは、取れてほしいものが取れてるかだけ確認しておく。
1番染色体上には、Notch2とNotch2NL(A,B,C,R)遺伝子がある。この方法で、Notch2NLAを含む領域は検出できなかったけど、Notch2NLAとNotch2NLRを含む領域同士、NotchとNotch2NLCを含む領域同士の対応が取れてそうだった。まぁ、こんなんでも、そこそこうまくいくらしい。これらの遺伝子の位置は、以下のサイトを参照した。
NOTCH2
https://www.genecards.org/cgi-bin/carddisp.pl?gene=NOTCH2
NOTCH2NLA
https://www.genecards.org/cgi-bin/carddisp.pl?gene=NOTCH2NLA
NOTCH2NLB
https://www.genecards.org/cgi-bin/carddisp.pl?gene=NOTCH2NLB
NOTCH2NLC
https://www.genecards.org/cgi-bin/carddisp.pl?gene=NOTCH2NLC
NOTCH2NLR
https://www.genecards.org/cgi-bin/carddisp.pl?gene=NOTCH2NLR
染色体同士の比較だと、Notch2NLAが出てこなかったけど、Notch2NLAを含む8万bpちょっとの領域を切り出して、
lastz notch2nla.fa hg38/chr1.fa --chain --gfextend --gapped --step=20 --format=maf > notch2nla_vs_hg38_chr1.maf
みたいなことをすると、4つの相同領域が取れてる。どれも、6〜9万bpの長さで、Notch2を含む領域以外が取れてるっぽい。
これらの遺伝子は近くにあって、gene conversionによって、重複遺伝子間の相同性が維持されるようなことがあった(ある)と考えられているので、これらの遺伝子重複がいつ起きたか見積もるのは、簡単ではなさそう。
また、重複遺伝子が出現して、すぐに表現型が変化したとも限らない。表現型に反映されるには、遺伝子ができるだけでなく、発現の調節もされないといけない。長い間、偽遺伝子だったものが、ある時復活するということもありえる。
ボノボでは、別の染色体上に、遺伝子のコピーが挿入されている例を上で見たけど、ヒトにも同様の例はある。1番染色体上にあるNotch2NLAの近くには、HYDIN2というヒト固有の遺伝子があり、16番染色体にあった遺伝子HYDINから部分的な重複とgene fusionを経て形成されたものと予測されている。論文では、その出現は、約320万年前とされている(前提として、ヒトとチンパンジーの分岐年代を約600万年前と仮定している)。
The birth of a human-specific neural gene by incomplete duplication and gene fusion
https://doi.org/10.1186/s13059-017-1163-9
これも、機械的に抽出できるか実験する。
lastz hg38/chr1.fa hg38/chr16.fa --chain --gfextend --gapped --step=20 --format=maf > hg38_chr1_chr16.maf
として、1番染色体と16番染色体で、相同性の高い領域を探すと、10万bpを超える対が2つ見つかり、この2つは隣接しているので、一回の重複で生じたものかもしれない。そして、この領域は、HYDINやHYDIN2がある領域と重なっている。
この2つの相同領域対の全長は、1番染色体上で278kbp、ミスマッチ数の合計は1659で、ミスマッチ塩基の割合としては、大体、0.6%くらい。異なる染色体上にあるので、重複が起きた後、組み換えなどは起きなかったと考えてもいいだろう。
仮に、ヒトでSNVの増える頻度が、1.0e-9/site/yearだとすれば、このミスマッチ数が生じるまでにかかる時間は、1659/(2*278e3*1.0e-9)で、大体、300万年程度。元の論文より手抜きではあるが、論文の見積もりと、そんなに変わらなそうである。論文では、もう少し広い単一の領域を使って、チンパンジー、オランウータンのゲノムとのアラインメントも与えている。
論文の数字では、348kbpの領域に、分岐後、908と845の一塩基置換があったと書いている。この場合、ミスマッチ数は1753で、ヒトのSNV増加頻度が、1.0e-9/site/yearなら、このミスマッチ数が生じるのにかかる時間は、1753/(2*348e3*1.0e-9)で250万年程度。
最後に、20世紀〜21世紀初頭の"人類起源論"に関わる古生物学(古人類学)界隈の記述を中心に、いくつか集めてみた。
[1930年]人類の誕生地
https://doi.org/10.5026/jgeography.42.1
[1931年]人猿間の二動物
https://doi.org/10.5026/jgeography.43.187
放射年代測定以前の時代で、人類の起源が、アフリカ、アジア、ヨーロッパのどこにあるか議論されてたらしい。前者では、紀元前15000年前とか25000年前のヒトの制作物が発掘されたみたいな記述が散見されるが、人類自体の出現時期は言及されてない。後者も、更新世(約258万年前〜1万年前)という地質年代への言及はあるけど、具体的な年代の決定には至ってなかったのかもしれない。
[1951年]北京人類の失踪
https://doi.org/10.5026/jgeography.60.195
には、以下のようにある。北京原人の絶滅時期を75万年前としているけど、どうやって推定した年代なのかは不明。
この埃にまみれた眞鍮製の2個のトランクの中には今から75万年程以前に絶滅し,そして20世紀の初期に発掘せられ そしてまた第二次世界大戦の日本軍眞珠湾攻撃の直後再び行方不明となった原始人類の化石がおさめられてあるのである。
この失われた原人は北京人類(シナントロープス・ペキネンシス)と呼ばれるもので現在知られた祖先人類の中ではジャバの直立猿人とともに最古のものであり猿と人類との間では最も原始的なものと云われているのである
1960年代に、カリウム・アルゴン法による地質年代/化石年代の測定と、分子時計による分岐時期の推測が始まった。当時の分子時計は、タンパク質のアミノ酸配列に基づくもので、また化石年代をcalibrationに利用していた。
[1963年] Some Fallacies in the Study of Hominid Phylogeny
https://doi.org/10.1126/science.141.3584.879
この論文では、カリウム・アルゴン法の論文が、in pressとして引用されている(1964年に出版されたらしい)。本文中では、いくつかの化石記録から、
but most hominoid genera probably endured for at least 3 to 7 million years without much change of form.
という推測を述べている。
[1967年] Immunological Time Scale for Hominid Evolution
https://doi.org/10.1126/science.158.3805.1200
分子時計を用いた推定。分子生物学の結果ではあるが、ヒトと旧世界ザルの分岐時期を3000万年前と仮定した場合、ヒトと"African apes"の分岐時期は500万年前だと書いている。"African apes"と書いてるのは、ゴリラとチンパンジーのどちらが、ヒトに近縁なのか決定できなかったためらしい。実際、上で見たように、ゴリラとチンパンジーの分岐時期は比較的近い。
[1980年]東アフリカおよびエチオピアにおける最近の人類化石の諸発見
https://doi.org/10.1537/ase1911.88.1
カリウム ・アルゴン法により,この堆積物の年代は少なくとも359万年よりは古く,多分377万年ぐらいの古さを示している。 これらの化石はロサガムから出土した人類かどうか疑わしい顎化石(BEHRENSMEYER,1976)を除けば,東アフリカにおける最古の人類ということにな る。
[2003年]2つの人類起源論と人類のこれから
http://hdl.handle.net/10723/464
もっとも近縁のチンパンジーやボノボとの共通祖先から分かれて最初の人類が誕生したのは、DNAの研究からおよそ500~700万年前だと推定されている。これに対して、一昨年東アフリカから見つかったオロリンと命名された化石は、約600万年前のものだと推定されている。もしこれが、人類直系の祖先だとすれば、「ミッシングリンク」は、もはや存在しないことになる。
[2009年]ケニア,ナカリでの古人類学調査
https://doi.org/10.1537/asj.117.111
大分慎重な書き方にはなってるが、
私も,従来の分子生物学による分岐年代推定値は新しすぎると考える。これまで,オランウータンの分岐を1300~1200万年前とする推定が多い。これは,オランウータンの祖先種とされるシバピテクスの初出年代1250万年前に近く,整合性があるように見えるが,そうではない。
それならば,分岐年代が1500万年前よりも新しいことは考えにくく,それに合わせゴリラ,チンパンジーの分岐年代も下がるはずであろう。
などの記述がある。
分子生物学の名誉のために、TIMETREEを見ると、ヒトとオランウータンの推定分岐年代は、60の報告が列挙されていて、中央値は1520万年前となっている。ヒトとチンパンジー・ボノボの分岐年代と同様、推定の幅は広く、820万年前としているものがある一方、3000万年前としているものもある。
上の方に書いた通り、大型類人猿のSNV獲得速度が全部等しく一定であり、かつ、ヒト・チンパンジーの分岐年代が600万年前であると仮定した場合、ヒト・オランウータンの分岐年代は、1300〜1500万年前くらいになる。TIMETREEでは、ヒト・サルの分岐年代、ヒト・オランウータンの分岐年代の中央値は、640万年前と1520万年前で、概ね、辻褄は合っている。
TIMETREEは、この論説が書かれた2009年以降の報告も含んでいるけど、2009年以降、予測分岐年代が顕著に後ろにシフトしたということも、なさそう。TIMETREEにあるのは、基本的に、一次文献で、これらの文献の引用数は多分バラバラだろうから、個人が何となく多いと感じる中央値とずれることは、あるかもしれない。どれくらい引用数に違いがあるのかとか、気にならなくもないけど、それはそのうち調べよう。
近軸光学の群論的構造
近軸光学は、ガウス光学と呼ばれることもあるようだけど、ガウスの名前を冠するのが適切かどうか調べてないので、以下では、近軸光学と呼ぶ。
近軸光学は、19世紀から知られてたようだけど、どういうわけか、symplectic群が出てくる。19世紀には、まだsymplectic群の概念も名前も一般的に広まっておらず、また軸対称な系では、二次元シンプレクティック群しか出てこないので、本質は覆い隠されてもいる。
最近、必要になって、ちょっとだけ光学を勉強したのだけど、このsymplectic群が、何に由来して出てきてるのか、腑に落ちなかった。勿論、19世紀から知られてる事柄なので、深く考えず、幾何光学に近軸近似を入れて議論を追っていけば条件は出る。これは単なる初等幾何の話で、それ以上説明することもないように思えるが、symplectic条件の出現は、唐突な感じがした。別に、深く気にしなくても、実用上困ることは何もないけど、納得は全てに優先する。
1980年代頃から、近軸光学を相空間上で展開する議論が見られるようになってて、この相空間の正準変換と理解してもいい。けど、相空間の由来は明らかでなく、腑に落ちないことを、別の言葉で言い換えただけで、分からなさに大して変化はない。例えば、元の波動光学には、共形対称性があるが、近軸近似の結果、軸周りの回転以外、対称性は全部消えてしまったと言っていいのか分からない。symplectic群の作用も、純粋に数学的な操作と言うよりは、(レンズのような光学系という形で)"光に作用する"と解釈することから、波動光学レベルでの意味付けも存在するべきように思う。
状況を整理すると、光の偏極は無視するとして、以下のように4つの理論がある。
近軸近似
波動光学 --------------------------------> 近軸(波動)光学≒フーリエ光学
↑| ↑|
|| ||
"量子化"? || 高周波極限etc. "量子化" || 高周波極限etc.
|| ||
|↓ |↓
"幾何光学" -------------------------------> 近軸光学
近軸近似"光学"と書いてるけど、幾何音響とかでも同じことだし、将来、重力波が工学的に利用可能になったら、やっぱり同じ理論が適用されるかもしれない。ビームの線形伝搬の理論みたいなものは、大体、同じ形式を持つと思われる。超音波ビームなんかだと、非線形性が重要になるケースがあるらしく、非線形な方程式に近軸近似を入れることもあるらしい。
"Fourier optics"という名前は、別にフーリエが直接何かやったわけではなく、1968年出版の本"Introduction to Fourier optics"以降、一般的になったっぽい。波動光学に近軸近似を入れた時の議論が中心っぽいけど、本を読んだことなければ、勉強したこともなく、フーリエ光学が指してるテーマを、私自身は正確に把握してないので、ここでは、フーリエ光学という名前は使わない。
あと、通常の幾何光学は、自由空間中でも、共形対称性が、どこに存在するのか、よく分からないという問題がある。(線形)波動方程式の主表象とかbicharacteristicsが定義される場所を考えれば、幾何光学の展開される相空間は、4次元時空の余接空間という気もする。この相空間で、共形代数の作用を見るのは難しくないけど、幾何光学は、そういう風に作られてない。
波動光学→幾何光学の導出過程で、色々近似が入ってるので、共形対称性は、その途中でなくなってしまったのかとも思ったりする。けど、古典系と量子系の対称性は、微妙に修正が必要なこともある(中心拡大が必要だったり、対称性が破れたり)が、大体は、同じ対称性を持ってるはずで、共形対称性がないのに、"量子化"して、波動光学が出るというのは奇妙な話に思える。
観点を変えて、共形対称性を持つ粒子系とは何者か考えると、候補として、相対論的massless particleが思いつく。けど、相対論的massless particleの解析力学の定式化は、幾分明らかでなく、通常の幾何光学を、そこから導く方法も、私には分からない。この問題は、今は考えないことにする。
幾何光学を相空間で定式化した時、近軸近似の下で、ハミルトニアンがどうなるかは、例えば、1987年の以下の論文に書かれてて、特に、自由空間(あるいは屈折率が一定の媒質中)では、古典力学の自由粒子と同じものになる。
The Hamiltonian formulation of optics
https://doi.org/10.1119/1.14999
近軸光学が、古典力学の自由粒子になってるなら、近軸波動光学の基礎方程式は、シュレディンガー方程式であると期待したくなる。そうすると、上の段の近軸近似は、波動方程式から、"シュレディンガー方程式"を出すものじゃないといけない。
双曲型方程式から放物型方程式になるという点では、非相対論近似のようでもあるけど、"massless"な理論から"massive"な理論を出す形になるから、非相対論的極限とは違う。この操作を誰が最初に明示的に書いたのか、よく分からないけど、1960年代には既に知られてたらしい(ソ連では、Leontovich–Fockの1940年代後半の仕事に関連付けて知られてたっぽい)
とりあえず、1969年の文献として、以下のようなものがある。
Degenerate Optical Cavities. II: Effect of Misalignments
https://doi.org/10.1364/AO.8.001909
この論文では、この近軸近似による微分方程式が、Fresnel近似とconsistentであると簡潔に書いてある。Fresnel近似は、名前からして、19世紀には知られてたと思うけど、微分方程式のレベルで、どうなってるか、長い間、明確には意識されて来なかった事柄なのだろうと思う。
1980年前後に複数の人が、4次元シンプレクティック群の作用を見つけている。19世紀の古典的な近軸光学では、2次元symplectic群
しか出てないと思うので、これは進歩だと思う。
Optical beam and pulse propagation in inhomogeneous media. Application to multimode parabolic-index waveguides
https://doi.org/10.1007/BF00619920
Metaplectic group and Fourier optics
https://doi.org/10.1103/PhysRevA.23.2533
などの論文は、シュレディンガー方程式との類似から、4次元シンプレクティック群に至っている。
幾何光学的な議論のみから4次元シンプレクティック群を導出する議論は
Wigner distribution function and its application to first-order optics
https://doi.org/10.1364/JOSA.69.001710
Lie algebraic theory of geometrical optics and optical aberrations
https://doi.org/10.1364/JOSA.72.000372
などに見られる。
(今の場合は、2次元空間内の自由粒子の)シュレディンガー方程式が出たので、2次元のガリレイ代数が対称性として存在する。
1972年に、光学とは無関係に、複数の人(Niederer、C.R.Hagen)によって、(時間依存)シュレディンガー方程式の対称性が決定され、現在は、シュレディンガー群/代数と呼ばれている。シュレディンガー群/代数については、以下にも書いた。
常微分方程式のLie symmetryと宇宙の作者の気持ち
https://m-a-o.hatenablog.com/entry/2022/02/17/215722
シュレディンガー代数は、勿論、ガリレイ代数を部分代数に含むが、それより真に大きい。しかし、全ての(無限小)線形正準変換を含んではいない。シンプレクティック群とHeisenberg群の半直積は、Jacobi群と命名されていて、一次元の場合は、Jacobi群とシュレディンガー群は、同じものになるけど、高次元では、Jacobi群の方が真に大きい。
ついでに、波動方程式の(ノルム有限な)解の基底を取って、共形代数の作用を具体的に書いたものが以下にある。殆ど式しかないので、リンク先で参照した論文を読む方がいい。
so(n+1,2)の極小表現の実現
https://vertexoperator.github.io/2021/05/05/hermite_BDI_minrep.html
1983年の以下の論文は、"Metaplectic group and Fourier optics"では簡単に書かれてる導出を詳しく調べて、波動方程式のポアンカレ対称性と近軸近似におけるガリレイ対称性の対応関係を書いている。
Paraxial-wave optics and relativistic front description. I. The scalar theory
https://doi.org/10.1103/PhysRevA.28.2921
Paraxial-wave optics and relativistic front description. II. The vector theory
https://doi.org/10.1103/PhysRevA.28.2933
仕組みとしては、シュレディンガー方程式の質量を座標の一つと見なして、Fourier変換すれば、以下の形の微分方程式
が得られる。とかすれば、普通の波動方程式になる。あと少し計算すれば、近軸近似におけるガリレイ対称性は、波動方程式のポアンカレ対称性に由来することが分かる。分かってしまえば、簡単な算数ではあるけど、普通の近軸近似の導出は、これとは違う風に説明してて、対称性との関係が分かりにくい場合がある。
ちなみに、この論文には、3+1次元ポアンカレ代数の部分代数として、2+1次元(中心拡大項ありの)ガリレイ代数を含むという話の起源が、以下のような素粒子物理の論文にあると書いてある。
Model of Self-Induced Strong Interactions
https://doi.org/10.1103/PhysRev.165.1535
Galilean subdynamics and the dual resonance model
https://doi.org/10.1103/PhysRevD.9.471
また、1985年に、光学とは無関係の分野で、Newton-Cartan理論が、5次元重力理論から得られるという論文が出ている。
Bargmann structures and Newton-Cartan theory
https://doi.org/10.1103/PhysRevD.31.1841
Newton-Cartan理論は、非相対論的な重力理論で、Riemann幾何学より一般的な枠組みであるCartan幾何学に基づいて定式化されている。通常の重力理論、つまり一般相対論の非相対論的極限になると思うけど、確認はしてない。多分、これも、"近軸近似"と同種の話だろうと思うけど、どういう風に解釈すれば、同じと見なせるのか、私は理解してない。ちゃんと読んではいないけど、この論文の式(4.3)とか見ると、上に書いた近軸近似と似たような座標の取り方をしてはいる。
若干の疑問として、非相対論的電磁気学(Galilean electromagnetism)では、2種類の非相対論的極限が存在する(基本的には、斉次ガリレイ群の有限次元表現で分類されるのだと思う)。非相対論的重力理論は、一種類しかないのか気になるけど、光学とは関係ないので、別の機会に考えることとする。
ポアンカレ代数は、波動方程式の対称性の一部に過ぎないし、ガリレイ代数も"シュレディンガー方程式"の対称性の一部に過ぎない。1973年の以下の論文では、3+1次元ポアンカレ代数と2+1次元ガリレイ代数の関係を、共形代数と(空間次元2の)シュレディンガー代数に拡張している。
About the non-relativistic structure of the conformal algebra
https://doi.org/10.1007/BF01646438
https://inis.iaea.org/search/4072083
より一般に、(空間次元dの)シュレディンガー代数は、共形代数の部分代数になってる。そして、予想される通り、近軸波動方程式の対称性は、全て、元の波動方程式の対称性に由来する。方程式と関連して、説明されてる文献として、
The Schrödinger-Virasoro Lie group and algebra : from geometry to representation theory
https://arxiv.org/abs/math-ph/0601050
の2節などを見ると分かりやすいかもしれない。
ついでに、比較的最近の以下の文献には、シュレディンガー群は、共形群の極小軌道のstabilizer subgroupとして出ると書いてある。
Schrödinger Manifolds
https://arxiv.org/abs/1201.0683
波動方程式をシュレディンガー方程式に変換するのは、ぱっと見よりも数学的に自然な操作なのかもしれない。
ともあれ、光学とは関係ないところまで見れば、シュレディンガー群/代数と共形群/代数の関係は明らかにされていた。
シンプレクティック群は、何故出てくるのか?というのは、本当のところ、よく分からないけど、これは新しい事柄ではない。(isotropicな)調和振動子の対称性も、Niedererが1973年に計算していて、シュレディンガー代数と同型の代数になることが知られている。
The maximal kinematical invariance group of the harmonic oscillator
https://www.e-periodica.ch/cntmng?pid=hpa-001:1973:46::960
調和振動子の波動関数の空間に、Jacobi代数が作用していることは、比較的簡単に分かるし、割と、あちこちに書いてある(Jacobi代数という名前を使ってるかはともかく)。知る限り、今の所、それ以上の説明はないと思う。
そもそも、(中心拡大項付きの)ガリレイ代数は、Galilean boostと空間並進、質量演算子で、Heisenberg代数と同型な代数を作るから、ガリレイ代数の作用があるところには、いつでも、Jacobi代数が作用しているのかもしれない。
しかし、例えば、元の波動方程式にも、対称性より大きな代数が作用していて、近軸光学におけるsymplectic代数の作用も、そこから来たりしないのか?という疑問は、現時点では、よく分からない。
最後に、"幾何光学"を考える。通常の幾何光学は、自由空間で定式化しても、共形対称性を持ってない(ように見える)。それで相対論的massless particleの解析力学を作ればいいというのは、自然な発想と思う。相対論的massless particleの解析力学をどうすればいいのか、適切な文献もないし、自分で計算もしてないので、正解は分からない。
massless particleの相空間の作り方は、例えば、以下のような論文に書いてある方法がある。
Relativistic Symmetries and Hamiltonian Formalism - MDPI
https://doi.org/10.3390/sym12111810
共形代数の生成子を、Minkowski空間の位置座標と(四元)運動量で適切に書いてやれば、共形代数の生成子が極小軌道を定義するようにできる(はず)。これが、massless particleの相対論の相空間。四元運動量を運動量演算子にして、量子化してやれば、通常の共形代数の作用を復元する(べき)。余随伴軌道を自由粒子の相空間とするという考え方は、大雑把に言えば、自由粒子一個の状態空間を、対称性の群の既約ユニタリ表現空間と見るという発想の古典版であるとみなすことができる(興味あるケースの多くで、余随伴軌道とユニタリ表現の対応は明らかではないけれど)。以前からあると思うけど、誰が最初に述べたのかは調べてない。
共形代数の作用がわかってれば、massless particlの場合と、波動光学の場合で、近軸近似の操作は全く同じ形で書けるようになるはず。これによって、自由空間で4つの光学理論がconsistentになるように思う。数学的には自然な気がするけど、これが正しいのか分からないし、自由空間以外で、同様の定式化があるのかも不明。
光学の納得いかないところを、よく考えると、やっぱ、よく分からんという結論になった。
以上は、自由空間(あるいは、屈折率が一様な媒質中)の話で、レンズなどの光学デバイスは、自由空間を伝播する波動方程式の解を別の解に線形変換する装置のようにモデル化される。
屈折率分布がある場合でも、相空間で記述すれば、一般の幾何光学、近軸光学のどっちも、数学的には、古典力学系と同じ形式で議論できる。ちょっと面白い話として、Maxwell魚眼レンズという屈折率が一様でないレンズ(多分、現在まで制作されたものはない)が知られてて、球面上の測地流と"等価な"可積分系になるそうだ。
Maxwellのオリジナルの論文は、以下で読める。タイトルが"solutions of problems"と素っ気ない。
The scientific papers of James Clerk Maxwell p74〜p79
https://archive.org/details/scientificpapers01maxw/page/74/mode/2up
可積分系になることは、以下のような論文で書かれてる。
Kepler problem and Maxwell fish‐eye
https://doi.org/10.1119/1.11200
Hidden symmetry and potential group of the Maxwell fish‐eye
https://doi.org/10.1063/1.528979
ちゃんと読んでないけど、前者は、幾何光学レベルでの議論のみで、後者は、波動光学レベルの話も書いてある。これらの論文より早く、ソ連では、1971年に以下のような論文が書かれている。
Internal Symmetry of the Maxwell "Fish-eye" Problem and the Fock Group for the Hydrogen Atom
http://www.jetp.ras.ru/cgi-bin/dn/e_033_06_1083.pdf
多くの論文で、Kepler系との関係が強調されてるけど、Kepler系のハミルトニアンと、球面上の測地流やMaxwell魚眼レンズ系のハミルトニアンを結びつける(通常の意味での)正準変換があるわけではない。量子Kepler系と、球面上のラプラシアンのスペクトルを比較しても、2つの系が、単純に"等価"とは言えないことが分かる。
Kepler系と測地流の関係は、もう少し、ややこしい。最近の解説として、以下の文献は分かりやすいと思う。
The classical Kepler problem and geodesic motion on spaces of constant curvature
https://arxiv.org/abs/1411.5355
Maxwell魚眼レンズも、(線形)光学デバイスと見ることもできて、ABCD行列は、以下の論文などで計算されてるっぽい(計算をトレースはしてないので合ってるかは知らない)
Physical Optics Analysis Of Gradient Index Optics
https://doi.org/10.1117/12.962999
統計学の変容過程
英語のstatisticsは、ドイツ語のStatistikの訳とされていて、Statistikは、Gottfried Achenwallという人の1749年の著書で初めて使われたとされている。Statistikは、当初、国家の状態を定性的に考察する分野だったようだ。
19世紀には、statisticsに数量的な性格が加わり、欧米諸国では、統計局が設置され、官庁統計を収集・作成するようになった。少なくとも、最重要なのは人口統計だったと思われる。国内の状況に関しては、古来、世界中で税収を確保することを主な目的として検地などが行われてたけど、改めて仕切り直した理由は分からない。日本の場合、1871年に"統計司"という部署が設置され、この時に、"統計"という訳語が使われている。現代の日本にも統計局はあって、総務省の管轄らしい。国勢調査以外は何をしてるのか知らない。
19世紀に、国家によって、統計データの収集が広く行われたことは間違いないけど、"統計学"が、大学で積極的に教えられてたのかは分からない。19世紀に、日本で訳された統計学の教科書は、それほど多くはない。
工業統計改良論/エルンスト・エンゲル述 http://webcatplus.nii.ac.jp/webcatplus/details/book/10375840.html
統計須知/ポルトル著;ニウマーチ校 http://webcatplus.nii.ac.jp/webcatplus/details/book/918969.html
統計入門/ガルニエ著 http://webcatplus.nii.ac.jp/webcatplus/details/book/846401.html
統計論/Maurice Block著 http://webcatplus.nii.ac.jp/webcatplus/details/book/701285.html
統計学論/Johann Eduard Wappäus著 http://webcatplus.nii.ac.jp/webcatplus/details/book/628610.html
統計学/Moreau de Jonnès著 http://webcatplus.nii.ac.jp/webcatplus/details/book/556063.html
統計論/Max Haushofer著 http://webcatplus.nii.ac.jp/webcatplus/details/book/10523892.html
1886年に、スタチスチック雑誌というのが作られたっぽい(後に、統計学雑誌と改題)
スタチスチック雑誌 (1)
http://webcatplus.nii.ac.jp/webcatplus/details/book/29412819.html
何にせよ、本来の統計学は、そういう分野で、社会科学の中で多少定量的性質を持つとは言え、数学とは縁遠い。一般に、数理統計学の創始者とされるFrancis GaltonやKarl Pearsonは、別に、そういう伝統的な意味での統計学者ではない。彼らの動機が、進化や遺伝だったことは、よく知られてるし、国家の状態や社会科学には、殆ど関心を持っていない。そう考えると、現代の数理統計学が統計学を名乗ってるのは不思議に思える。どういう経緯を辿って、そんなことになったのか、以前から、気になってたけど、ちゃんと説明されてるのを見ないので、調べることにした。
まず、数学の中で、"数理統計学"という分類が確立する以前は、数理統計学の基礎研究(の少なくとも一部)が、確率・組み合わせ論に分類されてたことは確認できる。
Jahrbuch über die Fortschritte der Mathematik
https://www.degruyter.com/serial/jbfmath-b/html
という、1868年〜1940年代初頭まで、ドイツで概ね毎年出されていたレビュー誌がある。当時、出版された数理科学関連論文(数学と物理が多いが、扱うテーマは幅広い)の簡単な要約を載せたもので、網羅性は高かったようだ。まだ、論文数がさほど多くなかった時代だから成立し得た雑誌だと思う。
組み合わせ論と確率論(Combinationslehre und Wahrscheinlichkeitsrechnung)のセクションは、1868年の創刊時点からあって、1900年頃、年間30〜50程度の論文が、ここに分類されている。Karl PearsonやFrancis Galtonは、1900年頃の常連。他に、1900年頃の有名人としては、ロシアのMarkovやスウェーデンのCarl Charlier(Charlier多項式やGram-Charlier展開に名前が残っている天文学者)などの名前も見つけられる。
この雑誌は1940年代まで続いたけど、オープンアクセスになってるのが、1905年くらいまでのものしかないようなので、後に、Mathematische Statistikとか、そんな感じの分類が追加されたのかは、確認できてない。
19世紀の時点で、確率論は、それほど大きな分野ではなかったが、いくつかの新しい応用先を見つけつつあった。誤差論と最小二乗法は応用というほどのものでもないけど、時折、関連する論文が書かれている。それ以外では、保険数理や砲術が、応用分野だろうと思う。19世紀日本では「確率」という訳語ではなく、「公算」と呼ばれていたようだけど、1891年の
公算学射撃学教程
https://dl.ndl.go.jp/info:ndljp/pid/844757
という本がオープンアクセスになってる。砲術への確率論の応用が、いつ、誰が始めたのか説明している文献は見当たらないので、詳細は分からない。
保険数理は、18世紀には既に存在していたけど、確率論を持ち込んだのが、誰なのかは調べてない。Laplaceの確率論の本(英題:A philosophical essay on probabilities)には、"生命,婚姻および任意の団体の平均持続期間について"という章が含まれてる(どういう内容かは読んでない)。1838年には、イギリスのDe Morganによる本"An essay on probabilities, and their application to life contingencies and insurance offices"が出版されている。このへんが、起源なのかもしれないけど、見出ししか確認してないので、嘘かもしれない
英語では、アクチュアリーという名前が、当時、既に使われていて(1848年にイギリスでInstitute of Actuariesが設立されている)、統計学とは区別されていたようだし、現在でも、統計学とは違う扱いをされるのが一般的と思う。
もう一つ、紛らわしいことではあるけど、"数理統計学"という名前は、19世紀のドイツ語圏に存在していたけど、それは、現在の数理統計学とは別物だったっぽい。ドイツでは、1869年に
Abhandlungen aus der mathematischen Statistik
https://books.google.co.jp/books/about/Abhandlungen_aus_der_mathematischen_Stat.html?id=PUZg8BjPbz8C
という本が出ている。この本は、前書き(Vorwort)を読むと、Bevölkerungsstatistik(vital statistics)に確率論や組み合わせ論を適用する旨が書かれている。また、保険数理(Theorie der Versicherungen)は、"mathematischen Statistik"には含めないとも書かれている。特に、影響を受けたらしき人として、Georg Friedrich Knappの名前が挙げられている。
著者はGustav Zeunerという人で、Wikipediaでは、工学者に分類されている。1848年にフライベルグ鉱山学校(※)に入学したとか、1875年にフライベルク鉱山学校の力学の教授となったとか書いてあるので、人口統計の分析は本業ではなく、また、数学者でもなかったらしい。フライベルグ鉱山学校の出身者には、アレクサンダー・フンボルトやエルンスト・エンゲルなどがいる。由緒正しい大学らしい。
Georg Friedrich Knappは、Wikipediaでは経済学者に分類されていて、1867年に、ライプチッヒ統計局のdirectorになったと書いてある。Knappは、伝統的な意味での統計学者だったと言っていいだろう。そして、Zeunerの本は、人口動態統計に、確率論を応用しようと試みたということらしい。
1906年や1910年に、ドイツで出版された"mathematische Statistik"の教科書も、目次を見る限り、内容的には、こうした話の延長なのかもしれない。1910年の本は、タイトルにLebensversicherung(life insurance)が含まれてるが、Statistikと区別されてる。表紙にはmathematische Statistikの文字も見える。
Vorlesungen über mathematische Statistik
https://archive.org/details/vorlesungenber00blasuoft
Wahrscheinlichkeitsrechnung und ihre Anwendung auf Fehlerausgleichung, Statistik und Lebensversicherung, 第2巻
https://books.google.com.sl/books?id=6iDOAAAAMAAJ
改めて、Jahrbuch über die Fortschritte der Mathematikを見ると、第1巻や第2巻の時点で、組み合わせ論と確率論のセクションに、Statistikをタイトルに含むものが見られる。検索しても、どういう人なのか不明なことが多いけど、これらは、vital statisticsを指していたのかもしれない。
21巻の組み合わせ論と確率論のセクションには、Arthur Newsholme(公衆衛生の専門家らしい)の1889年の著書
The Elements of Vital Statistics
https://books.google.co.jp/books/about/The_Elements_of_Vital_Statistics.html?id=oXsjAAAAMAAJ
の書評(?)らしきものが掲載されている。
19世紀後半〜20世紀初頭に、vital statisticsの分野に確率論を応用し、保険数理とは区別されてて、この分野を、特に、"数理統計学"と呼ぶ用法がドイツ語圏で存在していたらしい。これらは、伝統的な"統計学"に数学を適用した分野ということができるけど、現在の数理統計学が、これらの研究の延長上にあるというわけでは別にない。
19世紀後半には、(数理科学者ではない)一部の経済学者たちも、経済学に確率論を使おうと試みていたっぽい。元々の統計学と経済学は縁が深い。ドイツでは、1863年に、Jahrbücher für Nationalökonomie und Statistik(Journal of national economy and statistics)という雑誌ができてる。ある種の社会現象を数量的に把握しようとする"統計学"と、最初から価格という数量尺度が存在する"経済学"には、共通点があると思われたのかもしれない。
当時のイギリスでは、まだeconomicsという名前が使われておらず、該当分野を指すのに、political economyと呼ぶのが一般的だったらしい。多くの地域で、貨幣鋳造権が国家や権力者に管理された歴史を思えば、経済学が、法学や政治学の中の一つのテーマのように扱われることは不思議じゃないかもしれない。また、アリストテレスが「ニコマコス倫理学」で貨幣論を論じた伝統を継いでなのか分からないけど、19世紀後半になっても、道徳科学から経済学へ至った有名人が結構いる。
19世紀には、経済学部というものも殆ど存在してなかった。19世紀以前の人物が"経済学者"かどうかは、職業や学位によってではなく、現在"経済学"の著作と認められている本を書いたかどうかにで判定されてることが多いように思われる。本題とは関係ないし興味もないけど、当時の経済学は実証的な分野でなく、今と目的意識が同一だったのかも分からない。
そんな19世紀でも、経済学に、(確率論に限らない)数学的手法を持ち込もうという試みは、色々と存在してたらしい。通説では、Antoine Cournot(1801〜1877)あたりが嚆矢とされ、イギリスのWilliam Jevonsは、1862年に、General Mathematical Theory of Political Economyというタイトルの本を出版している(内容は知らない)。
Jevonsは1874年に、"The Principles of Science"という本を出版していて、この本自体は、経済学の本じゃないけど、その中には、確率論への言及も見られる。
The principles of science
https://archive.org/details/theprinciplesof00jevoiala
経済学への確率論の応用は、イギリスのFrancis Edgeworthあたりから本格的に始まるっぽい。Edgeworthは、1891年に創刊したthe Economic Journalの最初のeditorでもあり、1891〜1922年まで、Oxford大学の"Drummond Professor of Political Economy"(経済学のドラモンド教授職?ドラモンドは人名)を務めた。なので、一般的に、本分は経済学者と理解されている。Edgeworthは、数理統計学でも名前が残っていて、1880年代には、確率に関する論文を沢山書いている。
イギリスには、Journal of the Royal Statistical Societyという統計学会誌が存在し、1834年から現在まで続いている。当然、最初は、数理的な内容は殆どなかっただろう。
Mathematics in the London/Royal Statistical Society 1834-1934
https://www.jehps.net/juin2010/Aldrich.pdf
によると、1883年から、"regular mathematical contributions"が始まり、50年の間、minor partに留まったと書いている。1883年の論文とは、Edgeworthによる小論のこと。
On the Method of Ascertaining a Change in the Value of Gold
https://www.jstor.org/stable/2979314
また、Edgeworthは、1885年に同雑誌で
Methods of Statistics
https://www.jstor.org/stable/25163974
を寄稿している。内容的には、Edgeworthの独創というより、Galtonの以前の研究の紹介みたいな雰囲気を感じるけど、"統計学"を再定義しようとしているようにも読める。
Edgeworthは、Statistics(大文字)には、3つの定義があると述べ、第一の定義を、the arithmetical portion of Social Science、第二の定義を、"the science of Means (including physical observations)"、第三の定義を、(the sience?) of those Means which are presented by social phenomenaと述べている。そして、"平均の科学"に、主要な問題は2つあると述べ、一つは、平均値の差が偶発的なものか意味のある法則か決定すること、もう一つは、どの平均を使うのが最適か発見することと書いてる。
第一の問題は、平均値の差の検定に繋がる発想で、現在、"有意差"という言葉は頻出するので、差の検定は、統計学の代表的使用例という気はする。しかし、Edgeworthは、今日の仮説検定を完成させたわけでもないし、Laplaceは、18世紀に、男女の出生率が等しいと考えられるか、実データを基に確率的考察をしているから、新しい発想というわけでもないだろう。
正規分布に従う二群の平均値の差が偶発的か判定するには、分散を計算する必要がある(Edgeworthは、分散の2倍の平方根をmodulusと呼んでる)。Edgeworthは、実データから分散を決定するために、標本分散・不偏標本分散以外に、Airyの方法とGalton-Quetelet methodというものを紹介している。Galton-Quetlet methodは、1874〜5年頃、Galtonが、
On a Proposed Statistical Scale
https://doi.org/10.1038/009342d0
Statistics by intercomparison, with remarks on the law of frequency of error
https://galton.org/bib/JournalItem.aspx_action=view_id=44
などに書いてた方法で、正規分布では、第一四分位点と第三四分位点の距離が、modulusの2倍 x 0.476になることを利用する(erfinv(0.5)≒0.4769)。ベルギーのアドルフ・ケトレーも、原理的に同じ方法を使ってたと書いている。
Edgeworthは、イギリス人男性の身長分布を正規分布でfittingしてるけど、元データは、Francis Galtonらによる1883年の報告で
Francis Galton as Anthropologist
https://galton.org/anthropologist.htm
というページにPDFへのリンクがある。タイトルは"Final Report of the Anthropometric Committee"。
この報告には
The difference between the averatje and mean of a number of observations, and its importance in dealing with the subjects under consideration, has been pointed out and discussed by Mr. Roberts in the Report for 1881
という記述があり、このmeanという単語の使用は、ケトレーに従ったと書いてある。Mr. Robertsというのは、多分、Charles Robertsという人のことで、1870年代に、anthropometryという英単語を作った人と思われる。1878年に、Manual of Anthropometryという本を出版しており、
A manual of anthropometry
https://archive.org/details/manualofanthropo00robe
69ページで以下のように説明している。
An average is obtained by dividing the sum of the values observed by the number of observations, while a mean is the value at which the largest number of observations occur.
この時点でのmeanは、最頻値を指してるっぽい。一方、Edgeworthは、Meanという単語を、今日の"平均"の意味で使ってるように読める。この本には、数理統計学の色彩は皆無と言っていいと思うけど、statisticsという単語はよく出てくる。引用文献を見てると、millitary statisticsというフレーズも見られる。徴兵検査の際に行われる身長測定は、かなり古くからあるようで、それと関連してるのかもしれない。ヨーロッパでは、18世紀の記録も存在しているらしい(大体、ヨーロッパ諸国で常備軍が採用されるようになった初期からあったということだろう)。
Edgeworthの論説の中には、"統計学"から生まれた固有の数学概念と言えるものは、何もない。平均や分散の概念は、別に、"統計学"から出てきたものではない(averageという単語の起源は、アラビア語に遡れるらしい)。実データから、平均や分散を計算することも、"統計学"の専売特許ではない。
Francis Galtonは、親子の身長の関連を定量化しようとして、1880年代後半に相関の理論を作った。Galtonが、相関の理論を完成させるに当たって、伝統的な統計学が寄与したことは何もない。データは人類学で収集されたもので、親子の身長の相関という問題意識は遺伝への関心に起因するものだろうし、数学的には二次元正規分布の理論の応用である。
現代でも、相関を調べると、"統計学"という感じはあるし、分野によっては、データを集めて相関を見ただけという論文は量産されている。今は、相関のt-検定は一般的になってはいるけど、同時分布が(二変数)正規分布に従うかどうかの検定は、されてない(あるいは、書かれてないだけ?)場合が多いように思う。本来は、二次元正規分布という結構強い前提が存在してて、適用範囲は限られるはず。
相関の理論は、他の種類の統計データに適用できる手法ではあったけど、統計学の手法だったわけではない。1890年に、Galtonは、小論"Kinship and correlation"の最後の方で"相関"について、"There seems to be a wide field for the application of these methods to social problems."と書いて、社会科学の問題に、相関の概念を適用するよう示唆した。これを最初に実行したのが誰か知らないけど、1895年には、イギリスのGeorge Udny Yuleが、"On the Correlation of total Pauperism with Proportion of Out-Relief"というような論文を書いている。
Yuleは、Yule-Walker法やYule分布で、現在知られている。Wikipediaによると、ドイツのHertzの下で実験物理をやった後、1893年にイギリスに戻って、Karl Pearsonのdemonstrator(助手?)となったとある。
相関の計算は、比較的速やかに、複数分野で使用されるようになったっぽい。相関の理論が心理学で使われ始めた経緯は調べてないけど、以下のような文書がある
20世紀初頭における我が国での相関係数の普及について
https://waseda.repo.nii.ac.jp/?action=repository_uri&item_id=57867
ちゃんと調べてないけど、実験心理学の分野で確率的解析手法が使われるようになったのは、相関の理論が契機かは分からない。1897年の心理学の本
The New Psychology
https://archive.org/details/newpsychology025081mbp
の第二章のタイトルは、Statisticsになってる。
第二章の分量は少なく、相関の理論なども説明されてないけど、内容は確率論のもの。著者は、ドイツのヴィルヘルム・ヴントの所で心理学を学んだアメリカ人。本全体の内容は、生理学に近く、知覚などの問題が扱われている。20世紀の区分だと、知覚心理学とかに近いのかもしれない。もう少し細かく見ると、例えば、視覚情報処理を扱う場合、低次視覚機能が主になってるように思う。尤も、低次/高次の視覚機能という階層区分が当時認識されてたかは定かでない。心理学の門外漢からすると、心理学という単語からは、カウンセリング(臨床系の心理学)や意思決定の問題など、もっと高次の脳機能に関わるテーマを連想するけど、割と低レイヤの方から始まったらしい。
また、気象学では、Yule-Walker法のGilbert Walkerが、数学で学位を取得した気象学者で、統計的手法を持ち込んだ先駆者として知られている。
Yuleは、1897年に、Journal of the Royal Statistical Societyで、
Note on the Teaching of the Theory of Statistics at University College
https://www.jstor.org/stable/2979809
を寄稿している。
このノートで、Yuleは、英国で、"Theory of Statistics"の教育の必要性を訴え、Karl Pearsonが1891〜1894年に行った講義(lectures on the Geometry of Statistics, the Laws of Chance, and the Geometry of Chance)(Gresham lectureと通称される)に示唆されたと書いている。現在から考えると、1890年代は、現在の数理統計学で重要とされている概念の大部分が発見されてないのに気が早いと思うけど、確率論を使うという計画は示唆されている。
Yuleの仕事は多岐に渡っていて、1920年代に、ロジスティック方程式が、実際の人口動態に当てはまるか議論している(ロジスティック方程式自体は、1838年には発見されてたし、Yule以前にも先行研究はある)。ロジスティック方程式は決定論的な方程式で、数理統計学とは関係ないけど、人口統計は、本来の意味の統計データの代表なので、"統計学"の数学的研究と言えるかもしれない。
文章の統計的特徴から著者を特定しようという試み(Yule以前にも先行者はいたけど)も研究していて、1944年には、このテーマで"The Statistical Study of Literary Vocabulary"という本を出版した。
Yule-Walker法は、時系列解析の方法で、現在の(数理)統計学の教科書では、時系列解析の方法は書いてないこともある。分野によっては、時系列解析は全然使わないけど、"統計学"と題された現代の教科書の目次を何冊か見ると、社会科学系の人が書いた本では、時系列解析の説明を含んでることが多いっぽい。
1901年に、イギリスの経済学者Arthur Lyon Bowleyは、以下の本を出版した。
Elements of statistics
https://archive.org/details/elementsstatist03bowlgoog
この本は、伝統的な統計学の本のように見えるけど、後半のPart IIは、"APPLICATION OF THE THEORY OF PROBABILITY TO STATISTICS"というタイトルになっている。古典的な統計学と、現代の数理統計学を繋ぐ本と言えるかもしれない。Bowleyの本は、最後の10ページほどで、"相関の理論"を扱っている。
冒頭では、"Statistics"の定義を述べている。色々書いてあるけど、Bowleyの定義では、沢山の数量データを扱うのが"統計学"みたいなニュアンスっぽい。
1902〜1909年の間に、Yuleは、数理統計学の講義を行い、講義を元にした本が、1911年に出版された。
An Introduction Of The Theory Of Statistics
https://archive.org/details/in.ernet.dli.2015.260515
1902〜1909年の間に行った講義を元にしているというのは、初版のprefaceに書かれている。1922年には第6版が出ているので、かなり広く読まれたようである。Bowleyの本と比べると、"相関"の概念が前面に押し出されている。
Yuleの本には、"mathematical statistics"とは書かれてないけど、これは完全に"数理統計学"の教科書と言っていいと思う。統計的仮説検定はまだないけど、manifold classificationという章で、カイ二乗値の計算が説明されている。
Yuleの本には、英語のstatisticsという単語の由来や意味の変化が最初に述べられている。それによると、W. Hooperが1770年に出版した翻訳書(原著者はJakob Friedrich von Bielfeldという人と思われる)の中に、Statisticsと題された章があって、英語でstatisticsという単語が最初に使われたとしている。statisticsの主題は、“The science that teaches us what is the political arrangement of all the modern states of the known world"と説明されてる。
当初は定性的な分野だったが、19世紀に入ると、国家の状態を、数量的に把握するという側面が強調されるようになったらしい。彼らは殆ど漫然とデータを集めてたのに近いけど、平均を計算する以外に、何らかの指標を抽出しようという発想はあったと思われる。Yuleは書いてないけど、19世紀には、エンゲル係数で知られるエルンスト・エンゲルは、1850年にザクセン統計局初代局長、後にプロイセンの統計局長官を務めた。ケトレーは、BMIの考案者だそうである。これらの指標に、どこまで意味があるのか疑わしいけど、21世紀になっても、使われてはいる。
英語のstatisticsは、現在、「統計学」を指す場合と、「統計データ」そのものを指す場合がある。元々、"統計学"を指していたstatisticsだが、19世紀になると、一般の(大規模な)数量データを指して、statisticsと呼ぶ用法が出現した。そして、国家の問題に関わらない分野とデータについても、statisticsやstatisticalという単語が使われるようになった。
Yuleの本には書いてないけど、Francis Galtonは、1866年に、気象統計(meteorological statistics)という言葉を使い、1874年には、anthropological statisticsという単語も使ってる。物理で、"統計力学"という分野名を作ったのは、Gibbsだと思われる。Gibbsは、1884年に、"On the fundamental formula of statistical mechanics, with applications to astronomy and thermodynamics"という短い報告を書き、1902年に"Elementary Principles of Statistical Mechanics"という本を出版している。
Yuleの本には、"By statistics we mean quantitative data affected to a marked extent by a multiplicity of causes."と書かれている。そして、"(数理)統計学"を指す場合には、theory of statisticsを使用している。本のタイトルも、"統計学の理論"ではなく、"統計(データ)の理論"と訳されるべきなんだろう。Yuleは、本来の意味を超えて、statisticsやstatisticalが使われた事例を、いくつか挙げている。
Yuleが、theory of statisticsという名前を使ったのは、それが旧来のStatisticsの延長上にあったからではなくて、statisticsで数量データを指す慣習が広がっていたからということのように思える。そういう用法が広まってなかったら、この分野を指すのに、metricsとか、そんな感じの単語が使われてたかもしれない。
Yuleの本出版の翌年、1912年に、アメリカの経済学者Willford I. Kingは、以下の本を出版している。
The elements of statistical method
https://archive.org/details/elementsstatist04kinggoog?msclkid=20e1f7debb0f11ec992e696f7d298878
Chapter I Section10で、"Statistical method may properly be considered, a branch of mathematics"と書いてるし、目次を見ても、これは数理統計学の本と言っていいだろう。Kingの本も、第一章で、statisticsの歴史が書かれているが、Yuleの本と違って、statisticsという単語の意味の変化には注意を払ってない。
Chapter IのSection8で、"pure theory of statistics"の発展に貢献した人として、以下の名前を挙げている。
1)August Meitzen
2)Francis Edgeworth
3)Francis Galton
4)Edward Lee Thorndike: アメリカの心理学者
5)Karl Pearson
6)G. Udny Yule
7)Charles Benedict Davenport:アメリカの生物学者
8)Jacques Bertillon: 1883年からパリ市の統計局局長だったそうなので、ある意味で正当な統計学者と言える
9)Arthur L. Bowley: 1901年に"Elements of Statistics"を出版した経済学者
10)Reginald Hawthorn Hooker: 1901年に"移動平均"を発表した。Kingの本は、移動平均を紹介した最初の本だろうと思う。
11)Thos. S. Adams: 何者か分からないが、Kingの指導教官だったようである
12)Warren Persons: アメリカの経済学者らしいけど何をしたのか不明
(1)~(7)は、生物統計の人、(8)〜(12)は経済学の人としている。Edgeworthは、Biometrikaに投稿した論文も一本だけあるが、一般的に、経済学者として知られているので、生物統計の人に分類されてる理由は不明。August Meitzenという人も、ドイツの統計局に務めた伝統的統計学者らしいので、生物統計の人に分類されてる理由は謎。
1900年頃までに、国家の状態を数量的に把握するための"統計学"とは別に、大規模数量データの確率的解析手法が開発され、それぞれの分野が、一般の社会現象や経済の"統計データ"にまで適用範囲を広げた結果、接点も生じていた。
とはいえ、伝統的統計学者で数理的手法に関心を持つ人は少なかったっぽい。これについては、"統計学"以外の分野も、大体同じだったんじゃないかと思う。例えば、生物学者の多くは、別に統計的手法を使わなかった(そして、生物学の重要な結果は、そのような手法を経ずに得られたと思う)。人数が少ない内は、特殊なアプローチを採ってる一派がいるというだけで、スルーされてても不思議はない。
1910年頃になっても、英語圏では、まだmathematical statisticsという用語は一般的には使われておらず、theory of statisticsだのstatistical methodだのという呼称が使われてた(イギリスと違って、アメリカでは、statisticsを"統計学"と"統計データ"の両方の意味に使用するのに躊躇しない傾向があったかもしれない)。UCLでDepartment of Applied Statisticsが設立されたのが1911年。
Ronald Fisherの1925年出版の著書は、"Statistical Methods for Research Workers"というタイトル。尤も、Fisherは、Introductionで、
Statistics may be regarded as (i.) the study of populations, (ii.) as the study of variation, (iii.) as the study of methods of the reduction of data.
と書いてるから、Statisticsで数理統計学を指してもいいと思ってたらしい。更に、以下のようにも書いてる。
Statistical methods are essential to social studies, and it is principally by the aid of such methods that these studies may be raised to the rank of sciences. This particular dependence of social studies upon statistical methods has led to the painful misapprehension that statistics is to be regarded as a branch of economics, whereas in truth methods adequate to the treatment of economic data, in so far as these exist, have only been developed in the study of biology and the other sciences.
アメリカの経済学者Willford Kingが、"pure theory of statistics"の開発に貢献した人として、経済学者も列挙してたのに対して、Fisherは、statistical methodsの開発に経済学者が貢献したことはないという立場らしい。
Journal of the Royal Statistical Societyでは、1930年あたりから、一年に一回、"Recent Advances in Mathematical Statistics"という紹介記事が掲載されるようになっている。
Recent Advances in Mathematical Statistics (1930)
https://doi.org/10.2307/2341934
1934年に、雑誌に、Supplement to the Journal of the Royal Statistical Societyという名称で、産業や農学研究のためのセクションが追加され、戦後になって、supplementは、Series B (Statistical Methodology)となったそうだ。
アメリカでは、1918年に"Introduction to mathematical statistics"という本が出版されて、1930年にAnnals of Mathematical Statisticsという雑誌が作られてる。
The Annals of Mathematical Statistics VOL. 1 · NO. 1 | February, 1930
https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-1/issue-1
最初のarticleで、以下のように述べられてる
For some time past, however, it has been evident that the membership of our organization is tending to become divided into two groups — those familiar with advanced mathematics, and those who have not devoted themselves to this field. The mathematicians are, of course, interested in articles of a type which are not intelligible to the non-mathematical readers of our Journal.
こうしたことを見ると、英語圏で、mathematical statisticsという呼称が一般化したのは、この時期のようである。
1930年のアメリカでは、Econometric Society/計量経済学会も作られている。econometricsという単語は、これ以後一般化したと思われ、それ以前の使用例は、Arthur Robert Crathorneという数学者が、1926年の記事で、econometryという名前を提案している以外に、発見できなかった。計量経済学会の設立時の会員を見ると、経済学者以外に、Walter Shewhart(統計的品質管理の考案者として知られる技術者)や、数学者Karl Menger(経済学者Carl Mengerとは親子)、Norbert Wienerが含まれている。初期メンバーは、全員アメリカ人(移民もいるが)で、イギリス人経済学者とかは、いないっぽい。
非英語圏の事情は、調べる(原文を読む)のに、膨大なやる気が必要なのでpass。以下の論文は、飛ばし読みしただけど、1920年代のフランスの事情が書いてある。Borelが頑張ったらしい
The emergence of French statistics. How mathematics entered the world of statistics in France during the 1920s
https://arxiv.org/abs/0906.4205v2
ドイツ、イタリア、オランダ、ロシアあたりの事情は分からないけど、以下の論文には、1910年前後のスウェーデンの事情が、どうだったか書いてある。スウェーデンは、現在も、数理統計学と統計学の区別があるみたいに書いてある。
Why Distinguish Between Statistics and Mathematical Statistics–The Case of Swedish Academia
https://doi.org/10.1111/insr.12275
[PDF] https://sites.stat.washington.edu/peter/history/mathstat.pdf
引用文献の多くが、スウェーデン語なので、細かいところまでは確認できない。ついでに、Charlierは1910年に、Grunddragen af den matematiska statistikenという本を出版しているらしい。
インドでは、1931年に、マハラビノスの主導によって、Indian Statistical Instituteが設立されてる。インドでは、1870年代に、最初の国勢調査が行われたようなので、伝統的な統計学者も存在してたんじゃないかと思うけど、詳しいことは分からない。
日本も、1940年代には、イギリスやアメリカの流れに追随することになった。1941年に、統計数理研究という雑誌が作られている。
統計数理研究
https://catalog.lib.kyushu-u.ac.jp/opac_search/?reqCode=fromsrch&lang=0&amode=2&smode=1&disp_exp=20&kywd1_exp=bms&con1_exp=c_string_pubname
初っ端が、"量子統計力学の基礎"で、寄稿者の多くが、数学者や物理学者だったためか、初期には、通常の統計学よりも広いテーマが扱われてる。
統計学の未来
https://www.amazon.co.jp/dp/B096XT44HK/
という1976年出版の本を読むと、1944年に、数学者が中心になって、統計数理研究所が作られ、設立メンバーは6人と書いてある(60ページ)。当時の日本には、社会科学としての統計学をやってる人が中心の統計学会があって、そういうのとは独立して、統計数理研究所ができたので揉めたみたいなことも書いてある(38ページ)。
社会統計学のエライ人は、高野岩三郎という名前が挙がっている。1903年に留学から戻った後、20世紀初頭に、東京帝国大学などで統計学の講義を行い、また、戦後の1948年に日本統計学会初代会長にもなったらしい。Wikipediaで日本統計学会の歴代会長を眺めると、初期は、大体、経済学者っぽい
高野岩三郎による、大正12年度(1923年?)の講義録が、以下で見れる。数学的な内容は含んでないと思う。
統計学 [高野岩三郎 述]
https://dl.ndl.go.jp/info:ndljp/pid/927574
統計数理研究所が設立されたのは、戦時中なので、軍事に貢献することが当然要求された。「統計学の未来」には、生産管理や品質管理をやってたみたいなことが書かれてるけど、詳しいことは分からない。雑誌「統計数理研究」の中には、以下の論説がある。
米國數理統計學會の戰爭準備委員會の報告 : The Annals of Mathematical Statistics Vol.XI(1940) No.4
https://catalog.lib.kyushu-u.ac.jp/opac_detail_md/?lang=0&amode=MD100000&bibid=12901
1940年に書かれたもので、数理統計学者が、どういう問題で国防に寄与できるかというテーマが、9つ挙げられている。
(1)品質管理及び規格
(2)試料抽出による調査
(3)諸種の実験: Fisherの実験計画法への言及が見られる
(4)人的資源の選択: 人材の能力測定、特に、心理検査の解析に言及している
(5)用品及び食糧: 衣服や食糧資源の効率的分配への利用が言及されている(具体的方法は不明)
(6)運輸及び通信: 輻輳問題の解決に統計学が利用できるだろうとしている
(7)砲撃及び爆撃
(8)気象学
(9)医薬: 薬品、毒物の毒性の実験と解析に触れている。(3)と重複してる気もする
国防の観点から論じられてるので、実用性重視ではあるのだろうけど、当時の統計学への認識が分かる。最も詳しいのが、(1)なので、統計的品質管理は、一番重要と思われてたんだろう。統計的品質管理は、1924年に、ベル研究所のWalter A. Shewhart(1930年に設立された計量経済学会の初期メンバーでもあった)が始めたと一般的に説明される。Egon Pearsonも、1935年に、統計的品質管理の本を出版している。
二次大戦前後の時期に、日本で出版された"統計学"の教科書を探すと、沢山ある。以下は網羅的であることを意図したものではなく、Webcat plusで目次を見ることができるものをピックアップした。数が多いので、それでも抜けがあるかもしれない。
[1927年]統計学/竹下清松著 http://webcatplus.nii.ac.jp/webcatplus/details/book/887629.html
[1929年]統計学/汐見三郎著 http://webcatplus.nii.ac.jp/webcatplus/details/book/903401.html
[1930年]統計学/横山雅男著 http://webcatplus.nii.ac.jp/webcatplus/details/book/755736.html
[1932年]数理統計学概要/成実清松著 http://webcatplus.nii.ac.jp/webcatplus/details/book/893524.html
[1937年]数理統計学/松村宗治著 http://webcatplus.nii.ac.jp/webcatplus/details/book/604460.html
[1939年]統計学の理論と方法/寺尾琢磨著 http://webcatplus.nii.ac.jp/webcatplus/details/book/904341.html
[1942年]統計学/大内兵衛訳 http://webcatplus.nii.ac.jp/webcatplus/details/book/546460.html
[1943年]統計学の理論と実際/塚原仁訳 http://webcatplus.nii.ac.jp/webcatplus/details/book/586631.html
[1944年]統計学/藤本幸太郎著 http://webcatplus.nii.ac.jp/webcatplus/details/book/682811.html
[1948年]統計学入門/寺尾琢磨著 http://webcatplus.nii.ac.jp/webcatplus/details/book/757690.html
[1949年]数理統計学/佐藤良一郎著 http://webcatplus.nii.ac.jp/webcatplus/details/book/239635.html
[1949年]統計学/宗藤圭三著 http://webcatplus.nii.ac.jp/webcatplus/details/book/621717.html
[1952年]数理統計学要説/成実清松,坂井忠次共著 http://webcatplus.nii.ac.jp/webcatplus/details/book/249004.html
[1952年]社会統計学と抽出理論/馬場吉行著 http://webcatplus.nii.ac.jp/webcatplus/details/book/213879.html
[1952年]統計学/内藤勝著 http://webcatplus.nii.ac.jp/webcatplus/details/book/1200300.html
[1952年]統計学概論/宗藤圭三著 http://webcatplus.nii.ac.jp/webcatplus/details/book/431813.html
[1954年]統計学/中川友長著 http://webcatplus.nii.ac.jp/webcatplus/details/book/293521.html
[1954年]統計学の理論と応用/淡中忠郎著 http://webcatplus.nii.ac.jp/webcatplus/details/book/258471.html
[1957年]統計学/水谷一雄,後尾哲也共著 http://webcatplus.nii.ac.jp/webcatplus/details/book/255892.html
[1960年]数理統計学/S.S.ウィルクス著 http://webcatplus.nii.ac.jp/webcatplus/details/book/270798.html
目次を見ると、戦前には、(数学的なものと、そうでないものの)二種類の"統計学"が、共存してた様子が見える。"数理統計学"という単語がタイトルに使われたのは、検索する限り、1932年の本が最初だと思われる。著者は、Egon Pearsonの下で統計学を学んだ人だそうだ。
1937年の数理統計学には、"仮説検定"の内容はなさそうだけど、1949年の数理統計学では、検定に、かなりのページが割かれるようになっている。戦後になると、数学者の書いた数理統計学の本だけでなく、経済学者や社会科学者の書いた統計学の本でも、数学的内容(相関や時系列分析)を含むようになり、非数学的な統計学は、(大学以降の教科書、専門書レベルでは)ほぼ消滅したように見える。
戦後も、経済学者たちの"統計学"と、数学者たちの数理統計学が存在してたように見える。1950年代時点では、数学者の書いた数理統計学の教科書は、"数理統計学"と題して区別される場合が一般的だけど、1954年の淡中忠郎のような例もある。前者の統計学は、今は、社会統計学と呼ばれることもある。
社会統計学と数理統計学(『統計通報』誌(1975-78年)での討論) : 学説史上の位置づけ
http://doi.org/10.14992/00010614
という文書が2014年に公開されてる。1950年代前半のドイツやソ連で、本来の"統計学"と数理統計学の関係を問う議論があって、数理統計学は、本来の統計学と全く別の分野と主張する人もいたらしい
面倒なので、原文を探してチェックすることまではしてないけど、例えば、ドイツでは、
マイヤーは, 数理的方法は応用数学の分野の構成部分である, 社会的諸現象と諸過程を数理的手法で分析できないのは自明である, 統計学は社会科学であり, 数理的科学ではない, 統計学は独立の国家学である
ソ連だと、以下のような人がいる。
スタラドウブスキーは 「統計学」 のタームが, 社会統計学にも, 数理統計学にも使われていることを問題視する。 この問題意識の背景にあるのは, 統計学がもともと社会経済現象の数量的把握を目的とした科学なので, その用語を使うことは妥当だが, 数学の一分野である科学にこの統計学という用語を使うことが適当でないという考え方である。
スタラドウブスキーはいわゆる数理統計学は 「蓋然性論にもとづく数理的な確率論」 と呼ぶべきであり,そこで社会科学的資料が使用されても,そのことでもってこの科学を統計学分野に所属せじめる根拠にはならない,と強調する。
これらの主張は正当なもので、応用確率論とかいう名前にしてれば、軋轢も生じなかった(し、"統計学史"も書きやすかっただろう)と思うけど、色々な事情が重なって、数理統計学という名前が広まってしまった。これらの主張とは真逆の極端な立場として、数理統計学を、自然現象と社会現象に適用できる普遍的方法と見なす人もいたと書いてある。
現在の実態として、いくつかの日本の教科書を見た限り、社会統計学は数理統計学の手法を大幅に取り込んで成立しているように見える。数理統計学の成果を早期に取り入れようとした経済学者たちの試みから発展したものなんだろう。社会現象に数理統計学を適用できない派は、日本にはいなかったか、滅んだらしい。
数理統計学自体は、(比較的簡単な)数学的事実の集まりなので、そこは信用できるとしても、暗黙の内に数学的な理想化が入ってるし、明示的な前提条件もある。社会現象のように人間集団を対象とする場合、実データが、これらの条件を本当に満たしてる(と考えて差し支えない)かは明らかでない。数理統計学は、現象の数学的モデルの一つに過ぎず、現実に適合してるかは、数学だけ見てても答えはない。それを確かめる方法は論理とか哲学ではなく、実験的な検証に依るしかない。けど、コイン投げや機械部品の寸法とかならともかく、人間の集団で検証するのは多分難しい。大抵の場合、何を見ればいいのかすら確かではない。結局、そのへんは曖昧なまま、形式的に、数理統計学を適用する方向に進んだっぽい。
数学を使う"統計学"が台頭しつつあったけど、数学を使わない"統計学"が、そのせいで滅んだのかは分からない。何にせよ、国家の状態を数量的に把握するための"統計学"が殆ど消滅した後に、数理統計学と社会統計学を眺めた人からすれば、その共通部分は、ほぼ数理統計学そのものになってたので、"統計学"は数理統計学と同義と考えるようになっても仕方ない。
ついでに、「統計学は科学の文法である」、英語だと"Statistics is the Grammar of Science"という文章の起源を探した。なんでか知らないけど、このフレーズは、2010年頃から見られるようになった。
基本的事実として、Karl Pearsonは、1892年に、"The Grammar of Science"という本を出版して、第二版が1900年に、第三版は1911年に出た。
The grammar of science (2nd edition)
https://archive.org/details/grammarofscience00pearuoft
The grammar of science (3rd edition)
https://archive.org/details/p1grammarofscien00pearuoft
検索する限り、どの版でも、この文言は含まれていない。OCRのミスという可能性は、あるかもしれないけど、この本が出版された時期は、まだ旧式の統計学もあった時代で、数理統計学を、単にStatisticsと呼ぶと、紛らわしかったのでないかと思う。
Google scholarやGoogle booksで検索したところ、英語では、以下の本の第4章冒頭、81ページにあるのが見つかった。2008年出版の本らしい。英語圏で、これより古いのは、今の所発見してない。
Statistics for Nursing and Allied Health
https://books.google.co.jp/books?hl=ja&id=yc-WIr2dZBwC&oi=fnd&pg=PA81
日本語だと、1991年初版の
統計学入門 (基礎統計学Ⅰ)
https://www.amazon.co.jp/gp/product/4130420658
の第一章冒頭に、
「自然は数学という言語で書かれた書物である」これはガリレイのよく知られた言葉である。近代統計学理論の基礎の建設者カール・ピアソン(1857-1936)が、統計学は「科学の文法」The Grammar of Scienceであるという有名な言い方を残しているのも、だいたいにおいて同じ意味である。
と書いてある。Amazonの試し読みで見たので、初版からあるのか不明。この本は" 東京大学教養学部統計学教室 編"とあり、日本では、影響力が大きかったと思われる。
(適当に検索して出てきた)Statistics Quotesと題されたページ
http://www.math.wpi.edu/Course_Materials/SAS/quotes.html
の冒頭に、この文言は書かれているが、Wayback machineに保存されていた2009年1月には、まだ記載がない。
https://web.archive.org/web/20090131070147/http://www.math.wpi.edu/Course_Materials/SAS/quotes.html
いつ追加されたか正確には分からないけど、2013年6月には存在せず、2014年10月には存在している。一例ではあるけど、2010年頃には、まだ、このフレーズは普及してなかったのだろうと思う。
少数電子系の高精度計算(1)
最近、"精密計算化学"みたいな分野が存在してほしい気持ちが、私の中で高まってきた(精密化学という名前は、fine chemistryの訳語に既に使われてる)。電子数が1〜4の原子や分子では、Hylleraasが始めて、James & Coolidgeらに拡張された変分計算が(Born-Oppenheimer近似を仮定した限りでは)最高精度なので、最初に、この方法を見ていく。
歴史
17世紀末〜18世紀前半に、Keplerの法則と(二体問題における)万有引力の法則の"等価性"が示された。また、概算では、地球と月に及ぼしている力と、地球が地表付近の物体に及ぼす力を比較した結果、同じ種類の力が働いてると推測された。万有引力の法則は、適用範囲が広くて新しい予測が沢山出るので、どれくらい強固な理論か試験されることになった。
簡単に出る予測として、地表付近の重力が高度変化する時の一次係数の値がある。変化率は、3メートルにつき100万分の一程度という割合(0.308mGal/m)なので、重力の精密測定が必要になる。実際は、地球の密度が一様でないので、高度補正が、どれくあい綺麗に出るかは分からないし、17〜18世紀に、測定した人がいたかも不明。一応、17世紀の技術でも、振り子の周期測定などから、重力の高度依存性を検出できただろう。1670年代に、Jean Richerは、振り子の周期が場所によって異なるのを発見してるから発想はありえたと思うけど、ボルダの振り子やケーターの振り子が開発されたのは18世紀末〜19世紀初頭。まあ当時はそんな測定しても、実用的な意味もなかったろう。
別の予測として、Keplerの法則で説明しきれない、月の軌道の精密計算が目標となった。これは実用的価値があったけど、三体問題なので計算は難しく、ニュートンやオイラーも解決できなかった。計算精度が低かったために、一時期は、万有引力の法則が厳密には正しくない可能性や、惑星や月の間に、複数種類の力が働いてる可能性も議論された。結局、1740年代後半に計算法の問題だと判明して、1750年頃、当時のエライ人たちは、(当時の測定水準では)月の軌道からは万有引力の法則の逸脱を検出できないと合意した。
この時点でも、月の軌道計算の精度は、実用的に十分な水準には達してなかったようで、1750年以後も、オイラーは計算法の改良に取り組んだ。オイラーも、これといった成果も残せず、月の軌道の精密計算は、19世紀にも課題として持ち越された。計算法の改良は、ハレー彗星の回帰時期予測にも適用されて、ハレーの予測を改善したらしい。ハレー彗星の回帰は、1758年末〜1759年に観察されたけど、予測と観測には、まだ大きな差があった。
量子力学の場合、Keplerの法則と似た立ち位置に、Rydbergの公式(やBohr模型)があった。水素原子に対する量子力学の予測は、それ単体で見れば、簡単なものを難しいものに置き換えただけなので、新しい予測として、ヘリウム原子や水素分子で、基底状態エネルギーの計算を試みた人がいた。
1927年1月出版の論文で、オランダの物理学者Øyvind Burrauは、水素分子イオンH2+に対して、シュレディンガー方程式を解いて、基底状態エネルギーを計算した。水素分子イオンは、一電子系なので、電子相関はない。
Berechnung des Energiewertes des Wasserstoffmolekel-Ions (H{2/+}) im Normalzustand
http://gymarkiv.sdu.dk/MFM/kdvs/mfm%201-9/mfm-7-14.pdf
論文には、1922年に、PauliとK.F. Niessenが(独立に)、古典力学に"量子化条件"を考慮することで、エネルギーの計算を行ったことが書いてある(計算結果がどうだったのかは書いてない)。Born-Oppenheimer近似の下では、エネルギーは核間距離に依存し、更に、このポテンシャルエネルギーを使って原子核に対するシュレディンガー方程式を解くことになる。普通、ポテンシャルエネルギー曲線は解析的な形では書けないので、二原子分子ではMorseポテンシャルのようなモデルを使ったり、もっと単純にエネルギー極小値点近傍で調和振動子近似を適用することが、しばしば行われる(Morseの論文は、1929年に出てる)。
Burrauの論文によると、エネルギーの極小値は、-16.29(eV)で、これに極小点近傍のゼロ点振動分0.07eVを加味して、水素分子イオンのイオン化エネルギーを、16.22(eV)と算出した。1926年に、James FranckとPascual Jordanが測定した結果によれば、水素分子イオンのイオン化エネルギーは、16.1(eV)だったそうだ。0.1(eV)程度の差があるけど、測定誤差の範囲である。
正確な実測値が、どのくらいだったか覚えてないので、数値を確認しとくと、2017年の論文
Fundamental Transitions and Ionization Energies of the Hydrogen Molecular Ions with Few ppt Uncertainty
https://doi.org/10.1103/PhysRevLett.118.233001
には、QEDで、H2+のイオン化エネルギーを、12桁精度まで計算した値(自分で確認はしてないので合ってるかは知らない)が書いてあって、131058.121993(cm-1)=16.24913(eV)程度らしい。1920〜1930年代頃の論文を見てると、1Ry=13.53(eV)という数値が使われてて、今と単位の基準が違ったか、単位電荷の測定精度が低かったかしてたっぽい。単純比較はできないものの、Burrauの結果は、かなりよく測定値を再現してたと思われる。
Burrauの論文には、1926年に水素分子の解離エネルギーが測定されて、4.4(eV)だったことも書いてある。これも、一応、数値を確認しとくと、
(H2の解離エネルギー)=(H2のイオン化エネルギー)+(H2+のイオン化エネルギー)-2*(Hの基底状態エネルギー)
で、H2+のイオン化エネルギーは上に書いた通りの値を採用して、H2のイオン化エネルギーは、
Hydrogen@NIST Webbook
https://webbook.nist.gov/cgi/cbook.cgi?ID=C1333740&Mask=20#Ion-Energetics
の数値だと、15.4259(eV)程度。従って、H2の解離エネルギーは、16.24913+15.4259-13.598433*2=4.478164(eV)≒432(kJ/mol)程度と計算できて、1926年の測定値4.4(eV)は、そこそこ正しそう。
1927年4月付けの論文で、Edward Condonという人は、水素分子イオンの計算と、ヘリウムの第一イオン化ポテンシャルの測定値を使って、水素分子の解離エネルギーを、4.4(eV)と見積もれると書いている。Condonの議論は言葉で書かれてる部分が多くて、妥当なのかは分からない。この議論を信用するなら、ヘリウムの基底状態エネルギーが正確に計算できれば、水素分子の解離エネルギーも、当時の測定誤差と同程度の精度で計算できることになる。Edward Condonは、Franck-Condon原理で知られる人と同一人物だと思う。
1927年に、Albrecht Unsöld、John Slater、Georg W. Kellnerという人らが、独立に、シュレディンガー方程式に基づいて、ヘリウムの基底状態のエネルギーを計算した。ニ電子系では、電子相関があって、電子相関を考慮すれば、高い精度で計算できるかは当時まだ未知だった(まだ電子相関という言葉はなかったけども)。
ヘリウムの第2イオン化エネルギーは、水素原子と同様に計算できるので、基底状態のエネルギーが分かれば、第1イオン化エネルギーも分かる。3人の計算法は全員異なっていて、一番精度の高い計算をしたのはSlater。論文の日付は1927年4月26日になってる。
The Structure of the Helium Atom: I
https://doi.org/10.1073/pnas.13.6.423
論文には、"摂動論"だと書いてるけど、現代の人が摂動論と聞いて想像する方法とは違うように見える(実は等価だったりするのかもしれないけど、よく考えてない)。方法はともかく、結果を見ると、第1イオン化エネルギーの計算値と測定値の差は0.13eVとなっている。論文には、計算値と測定値の一致は、very remarkableだと書いてある。当時は、Theodore Lymanの1924年の論文に記載されてた198298(cm-1)=24.586(eV)が実験値として採用されてた(Slaterの論文には、おそらく、1Ry=13.53eVとされてたことと関連して、24.586ではなく、24.48という数値が書いてある)
Lymanは、水素原子の離散スペクトルの内、遠紫外領域にある(Schumann plateというものを使って測定してたらしく、当時の論文には、Schumann regionとか書いてあったりする)ライマン系列の測定に成功した後、1915年には、極紫外領域にあるヘリウム原子の離散スペクトルのために、測定方法の改良を始めている。
1927年、HeitlerとLondonは、6月30日付けの論文で、水素分子の基底状態に対する簡単な計算を行った。Heitler-London理論は、0次の摂動波動関数(つまり無摂動波動関数)を使って、1次までの摂動エネルギーを計算した近似である。定量的には精度が低く、水素分子の解離エネルギーの計算値は測定値より1.5eVくらい小さい。論文では、ポテンシャルエネルギー曲線のおおまかな形状を再現することが強調されている。
ヘリウムで、Heitler-London理論と同じように、基底状態のエネルギーを、一次の摂動項まで考慮して計算すれば、-2.75(au)になって、測定値−2.903(au)との差は、4(eV)強。多分、この計算は、Albrecht Unsöldがやったのが最初だと思う。1929年に、Slaterは、一般の多電子原子に対する同様の計算を行い、1次の摂動項まで考慮した基底状態エネルギーと、Hundの規則が整合的であることを示した。
摂動論が期待通りに機能するなら、高次の摂動まで考慮することで、水素分子でも、多電子原子でも、エネルギーと波動関数を精密に計算できるはず。こういう方針で証明や計算が行われたことがあるのかは分からないけど、多分、収束は遅い。
一般論として、二次の摂動エネルギーを計算するには、一次の摂動波動関数が必要になり、ヘリウムの場合は、厳密に解析的な関数で書ける(この事実は、多分1950年代末に発見された)。水素分子の場合には、多分、一次の摂動波動関数すら解析的には計算できないので、無摂動ハミルトニアンの固有関数で展開することになる(通常、無摂動ハミルトニアンは、連続スペクトルを持ち、それを無視するのは正しくない気がするけど、扱い方が分からないので、固有値と固有関数のみが計算に使われることになるのだと思う)。
一次の摂動波動関数が厳密に分かるヘリウムの場合、二次までの摂動エネルギーを計算に入れても、まだ測定値との差が1(eV)以上残る。Slaterが、1927年の論文で、ヘリウムの計算を、どうやったのか詳細を見てないけど、計算値と測定値の差が0.13eVだったのは、割と健闘してたと言える。
Hetiler-London流の摂動計算は、精度が低かったけど、比較的すぐに多原子分子に拡張された。1910年代には共有結合の定性的モデルは存在していたけど、Heitler-Londonの理論の延長上に、共有結合の量子力学的解釈が行われた。実際のところ、無摂動ハミルトニアンを、どう取るかは自由なので、原子軌道を特別な基底と思う先験的な理由は別にないはずだけど、現在でも化学結合の定性的説明が、このような方法で与えられる。普通、数式とかは使わずに説明されてるので、それが摂動論的描像なのは分かりにくい。
イギリスのDouglas Hartreeは、1928年に出版された論文(受領は1927年)
The Wave Mechanics of an Atom with a Non-Coulomb Central Field. Part II. Some Results and Discussion
https://doi.org/10.1017/S0305004100011920
の中で、Self-Consistent Field法とHartreeが命名した方法によって、原子やイオンの基底状態エネルギーの計算を実行した。特に、ヘリウムの第一イオン化エネルギーを、1.835(Ry)=24.97(eV)と計算してる。Hartreeの論文を受けて出版されたJohn Gauntの論文では、1.75(Ry)=23.81(eV)と計算するべきだろうと書いてあって、測定値との差は、0.8(eV)弱。Slaterの計算には及んでないが、上記の摂動計算よりはいい。
Hartreeの方法は、色々と修正や改良が加えられたものの、根幹部分は、Hartree-Fock近似として、現在も、計算化学で一番基本的な方法として生き残っている。けど、以下の1938年の論文を読むと、Hartreeの方法は、しばらくの間、多電子原子にのみ使われてて、多原子分子で使える方法にはなってなかったらしい。
Self-consistent field for molecular hydrogen
https://doi.org/10.1017/S0305004100020089
現在では、Hartree-Fock法は、分子軌道法の一部のように扱われるけど、1930年代の時点では、2つの方法は区別されていた。分子が扱えない方法に、分子軌道も何もない。分子軌道法は、1929年のLennard-Jonesの論文に始まると大体書いてある。定量性は低いけど、今でも教科書に書かれてるヒュッケル法などが、当時の分子軌道法の代表例。現在、計算化学で、分子軌道の係数の初期値を決めるのにも、拡張ヒュッケル法というものを使う。
1928年に出版された論文で、Shou-Chin Wang(王守竞)という人は、水素分子に対して、単純な非線形試行関数を用いた変分計算を示した。Wangの使った試行関数は、ただ一つのパラメータしか含んでなかった。が、Heitler-Londonの理論よりも、いい結果を与えた。
The Problem of the Normal Hydrogen Molecule in the New Quantum Mechanics
https://doi.org/10.1103/PhysRev.31.579
ヘリウムについて、同様の変分計算は、1927年のKellnerの論文に書かれている。
Die Ionisierungsspannung des Heliums nach der Schrödingerschen Theorie
https://doi.org/10.1007/BF01391720
この変分計算は、今でも教科書で見かけることがあるが、測定値と計算値との差は、1.5(eV)程度になる。Kellnerは、パラメータの多い試行関数でも計算を行ったが、複数パラメータを扱う時には、線形パラメータについてのみ変分計算を行い、非線形パラメータは決め打ちした値を使っているっぽい。最終的に得られた計算値は、Slaterが同年に与えたものより測定値との差が大きい。
1928年に、Egil Hylleraasは、線形試行関数を用いて、ヘリウムの基底状態の変分計算を行った。ここで使われた試行関数は、Kellnerの試行関数で、非線形パラメータを1に固定したものと見れる。論文に書いてある結果は、Kellnerのものより大分良くて、Slaterの計算と同程度の精度を達成している。KellnerやHylleraasの論文には、"Ritzの方法"と書いてあるけど、Ritzの1909年頃の論文でも、線形試行関数が使われてて、それに沿ったものと見ることが出来る。
1928年頃、ニ電子系でさえ、測定値と測定誤差の範囲で一致する計算値を出せてない。この惨状を、当時の物理学者や化学者が、どう思ってたのか分からないけど、Hylleraasは、ヘリウムの基底状態の計算精度に満足してなかったらしい。
Hylleraasは1929年の論文で、扱いやすい形の非線形試行関数を使って変分計算を行い、ヘリウムの基底状態のエネルギーを誤差0.01(eV)未満の精度で求めた。当時の測定精度を考えれば、これは十分と言える。
観測値とよく合う計算値が出たけど、Hylleraasの計算は、変分関数の極小値を出してるだけなので、真の極小値が、これよりずっと小さい可能性を否定しておかないと、理論の検証として十分とは言えない。基底状態エネルギーの下限を求める簡単な方法は、例えば、D.H.Weinsteinという人の1932年の以下の論文に書かれている。
A Lower Limit for the Ground State of the Helium Atom
https://doi.org/10.1103/PhysRev.40.797
論文の末尾に、この問題を示唆したのは、ポーリングだと書いてある。但し、ここでは、Hylleraasの論文で最良の結果を与えた試行関数ではなく、単純な波動関数を使ってるので、ヘリウム原子の基底状態エネルギーが、-3.1(hartree)よりは、大きいとしか言ってない。同じ方法で、Hylleraas試行関数を使って、下限の評価を行った論文は、1956年に出たものが最初と思われる。
1930年代には、Hylleraasの変分計算が、正しい値に収束することを疑う人もいたらしい。1937年には、以下のような論文が書かれている。
On the Convergence of the Hylleraas Variational Method
https://doi.org/10.1103/PhysRev.51.855
大分後の1977年に、Hylleraasの方法で、ヘリウムの基底状態エネルギーが厳密解に収束する証明をしたと主張する論文が出ている(以下のIIのTheorem10)。
The convergence of the Rayleigh-Ritz Method in quantum chemistry I
https://doi.org/10.1007/BF00548026
The convergence of the Rayleigh-Ritz Method in quantum chemistry II
https://doi.org/10.1007/BF00548027
尤も、収束するというだけなら、1927年のKellnerの基底や、1928年のHylleraasの基底でも収束はすると思う(IIのTheorem9は、Hylleraasの1928年の基底でも収束することを述べている)ので、現実的には、収束の早さも大切。この論文は、他にも色々書いてあって、GTO(Gauss-Type Orbital)基底が、正規直交基底をなすことの証明を、私は始めて見た。
1933年になって、Hubert JamesとAlbert Coolidgeという人が、Hylleraasの方法を拡張して、水素分子に適用した。James & Coolidgeは、計算値と測定値の差を、0.03(eV)と報告している。当時、水素分子の解離エネルギーの測定は、複数のグループで行われたが、総合的に見て、4.4〜4.5(eV)の範囲という程度の信頼性しかなかったようなので、測定誤差と区別が付かない程度の精度で計算できてたことになる。
水素分子に関して、James & Coolidgeの試行関数と、Shou-Chin Wangの試行関数を見比べると、1パラメータしかない時でも形が違っていて、Wangの試行関数の方が、いい結果を与える。
水素分子の励起状態の計算も、複数の方法で行われてたが、James & Coolidgeの方法の延長上に計算を行ったのは、1935年出版の
On the Two‐Quantum Σ‐States of the Hydrogen Molecule
https://doi.org/10.1063/1.1749607
だと思われる。James & Coolidgeも、水素分子の後、1930年代の内に、リチウム原子の基底状態と水素分子の励起状態を、同様の変分法で計算した。
結局、1930年代の電子状態計算法には、大雑把に言って、いくつかの半定量的方法、Hartree-Fockの方法(現在のHartree-Fock法と同一ではない)、Hylleraas型の変分計算の3種類があった。半定量的方法は、それ以前の化学の"理論"に比べれば、見かけ上の定量性は有してるけど、測定値を再現したり予測することは期待できない。1930年代には、一般の多原子分子を扱える方法は、半定量的なものしかなかった。現在では使うこともないと思うけど、1920~30年代に行われた半定量的計算は、今でも、量子化学の教科書には書いてある。現在流布している化学結合の定性的理解は、こうした方法に基づいて作られたものだし、新しい経験則を発見するのにも貢献してきた。
Hartree-Fockの方法は、現在のHartree-Fock法の礎になったけど、1930年代には、一般の多原子分子に使うことはできなかった。現在のHartree-Fock法に相当するアルゴリズムを、いつ誰が完成させたのかは、知らない。GaussianとGamessは1970年台にリリースされ、1970年代末には、post-Hartree-Fock法という言葉が使われるようになってる。タンパク質やDNAのような高分子の計算は現在でも難しいけど、化学者が必要とする多くの化合物の化学物性を、そこそこ定量的に計算できるようになっている。
Hylleraas流の試行関数を使った変分計算は、最大で4電子系までしか行われてないようである。Hylleraasの試行関数は、電子間距離を変数に含むので、電子数の二乗オーダーで、変数の数が増えることになるし、互いに独立でもなくなる。なので、電子数が多い時には、それほど効率的でなくなるのかもしれない。
もう少し電子数が多い場合には、CI計算が行われる。例えば、1974年には、以下の論文が出てる。
Configuration-Interaction Study of Atoms. I Correlation Energies of B,C,N,O,F, and Ne
https://doi.org/10.1103/PhysRevA.9.17
Hylleraas型計算は、化学者が知りたい化合物の化学物性を知るのには使えないけど、それでも電子数の少ない系では、今でも一番精度の高い計算法で、21世紀になっても、時々論文が出ている。
エネルギーを何桁くらいまで計算すればいいか考える。愚かな人類が、2〜3桁も合ってれば、よさそうと考えがちなのは、何を測定するにしても、2〜3桁より高い精度で測定するのは大変なことが多いからだろうけど、基本的な物理定数の測定誤差に由来する不定性を何桁も超えて計算しても、あまり意味がない。測定値と比較することを考えれば、相対論的補正より細かい精度を要求するかは、一つの基準になりそうに思える。他にも、原子核が点電荷でないことから来る補正とかもあるけど、評価しづらいので保留。
てことで、相対論的補正が、どれくらいなのか概算する。原子核の電荷をとした時、Bohr速度は、
になる。
は微細構造定数。
とおくと、相対論的補正は
くらいのオーダーだろうと思われる。例としてヘリウムの場合を考えると、だから、
は、2/137くらいで、相対論的補正は、0.01eVオーダーになる。リチウム原子の場合は、0.05eVくらい。
1eVは約96500(J/mol)で、100(kJ/mol)弱なので、0.01eVは、1(kJ/mol)のオーダー。リチウムの0.05eVは、1(kcal/mol)に近い。これは化学的精度と言われる数kcal/molくらいの水準に近いけど、最内殻電子の話で、通常の化学物性とかで影響が大きいのは外殻電子で、外殻電子では相対論的補正の影響は、もっと小さいはず。
現在の計算では、原子単位系を使うのが一般的で、原子単位系だと、0.05eVは、0.05/(13.6*2) ≒ 0.0018(hartree)なので、1.8ミリハートリーくらい。相対論的補正を無視する水準なら、ミリハートリーかサブミリハートーリー精度の計算が出来てれば、かなりいいだろうと考えられる。
常温300(K)が、エネルギー換算で2.5(kJ/mol)になって、ほぼ1ミリハートリー相当。これより弱いかもしれないけど知りたい場合がある相互作用として、分子間力がある。分子間力の大きさを概算する方法は思いつかないけど、文献値だと、He-Heで、30マイクロハートリーとかのオーダーになる。次に弱いNe-Neや、H2-H2で、0.1ミリハートリー程度。
超微細構造を見たい場合は、MHzオーダーまで計算の対象になり、参考値として、水素原子の2P状態の微細構造が10GHzオーダー、ラムシフトが1GHzオーダー。周波数では、1(kJ/mol)は、2.5(THz)くらい。1MHzは、0.1ナノハートリー程度。
というわけで、大雑把な目安として、
・単一分子の化学物性を見たいなら、ミリハートリー(これは、いわゆる化学的精度と同一オーダー)
・分子間相互作用を見たいなら、マイクロハートリー
・微細構造、超微細構造を見たいなら、ナノハートリー
くらいの計算精度が欲しいと考えられる。
現在のところ、超微細構造を見たい理由が、理論の検証以外にあるのか分からない。原子数の多い多原子分子とかで超微細構造まで見える精度の計算をしたい人は、あんまりいないだろう(簡単に計算できるなら知りたいかもしれないけど)けど、ヘリウム原子やリチウム原子だと、QED補正まで計算してる人もいる。そういう計算をする時は、非相対論的近似として、Hylleraas型試行関数を使った変分計算を出発点にしてることがある。
あと、無視されてることもあるけど、重心運動の自由度を分離した時に、核質量が有限であることから来る補正として、ヘリウムの場合は、mass polarization termというのが出る(何で、こんな名前なのかは分からない)。水素原子の場合は、mass polarizationはないけど、核質量が有限であることから、電子質量ではなく、換算質量を使うようにしないといけない。
水素原子の基底状態の電子エネルギーは、量子力学の教科書とか読めば、-13.6eVとよく書いてある。もうちょっと細かく見ると、0.5(Eh)=13.60569…(eV)で、Dirac方程式だと、13.60587…(eV)くらい。水素原子のイオン化エネルギーを、直接高精度で実験的に決定するのは難しいのか、あんまりデータがない。
Hydrogen atom@NIST Webbook
https://webbook.nist.gov/cgi/cbook.cgi?ID=C12385136&Units=CAL&Mask=20
には、イオン化エネルギーとして、13.59844(eV)という値が載ってるけど、methodがevaluationとなってるので、多分、計算値(?)。0.5(Eh)と比べると、0.26ミリハートーリー程度の差がある。電子質量でなく、換算質量を使ってシュレディンガー方程式の計算結果に放り込むと、13.59828…(eV)になって、記載値との差は6マイクロハートリー程度まで縮まる。
換算質量を使った方が文献値に近付くのが偶然でないことは、正電荷粒子が陽子より軽いポジトロニウムや、核質量が陽子より重い重水素などの水素様原子の基底状態エネルギーを調べると、はっきりと確認できるはず。逆に、NIST Webbookで見ると、重水素、三重水素の実験値は、13.603eVとなってて、核質量が重い場合、電子質量をそのまま使った計算値に近づいている。外場近似で、原子核の質量補正を扱う方法は、arXiv:hep-ph/0002158("Theory of Light Hydrogen Atoms")によると、1967年に提示されたそうで、何やかんやで、α^4までの項をQEDで計算すると、基底状態のエネルギーは、-13.598434…(eV)とかになって、記載値と近付く。
ヘリウムの場合も、電子質量ではなく、換算質量を使うようにしないといけないけど、それに加えて、mass polarizationという項が出現する。Hylleraasの1929年の論文では、Massenkorrektion bei Heliumという項で、換算質量による影響を評価してるっぽいけど、mass polarizationは考慮されてない。
以下の論文によると、1933年、Betheが、ヘリウムに対して、mass polarizationの評価を行ったことが書いてある(論文を読む限り、Betheの計算には、ミスがあったのかもしれない)。
Lower Bound to the Ground-State Energy and Mass Polarization in Helium-Like Atoms
https://doi.org/10.1103/PhysRev.103.112
この論文の数値を信じるなら、mass polarizationの影響は、0.02(ミリハートリー)程度なのだと思われる。この論文は基底状態エネルギー下限の評価も行ってて、1932年のD.H. Weinsteinの論文に書いてあるのと同じ方法だけど、Hylleraas試行関数に適用したため、下限値を大きく改善している。
核質量補正を忘れると、数学的練習問題を解いてるだけになってしまう。
ヘリウム原子(Hylleraasの計算)
既に書いた通り、Hylleraasも、最初は、Kellnerと同様、線形試行関数を使った。その後、非線形試行関数を使って、ヘリウム原子の変分計算を実行した。後者の論文は、以下。
Neue Berechnung der Energie des Heliums im Grundzustande, sowie des tiefsten Terms von Ortho-Helium
https://doi.org/10.1007/BF01375457
1956年に、木下東一郎が、試行関数を少し拡張して、また電子計算機を使用して、精度を上げた。この論文も、よく引用されている。この人は、電子の異常磁気モーメントの高精度計算がライフワークみたいな人だったっぽい。
Ground State of the Helium Atom
https://doi.org/10.1103/PhysRev.105.1490
Ground State of the Helium Atom. II
https://doi.org/10.1103/PhysRev.115.366
木下の論文では、mass polarizationによる補正と相対論的補正の計算もされている。
ヘリウムの電子数は2個なので、6次元空間上のシュレディンガー方程式を考えることになるけど、回転対称性を利用して、変数を3つまで減らせる。1つ目、2つ目の電子の原点からの距離をとして、電子間距離を、
とする。Hylleraasは、
という変数を使った。この変数で、シュレディンガー方程式を書き直すとかは面倒だけど、機械的な計算でできる。
Solving the electron-nuclear Schrödinger equation of helium atom and its isoelectronic ions with the free iterative-complement-interaction method
https://doi.org/10.1063/1.2904562
とかに、換算質量を使用し、mass polarizationも含む形で書いてある。ここでは、とりあえず、Hylleraasの結果を再現するために、換算質量も使わず、mass polarizationも考慮しない。
Hylleraasの使った試行関数は
という形のものと本質的には同じ(但し、qが奇数の時、係数は0)。uの奇数次の項は、原理的にはなくてもいい(つまり収束自体はする)けど、ないと収束は遅くなる。
非線形パラメータは一個だけで、このまま計算してもいいけど、Hylleraasは、多分、当時まだ電子計算機がなかったこともあって、もう少し工夫して
という形の関数にしている。こうすると、変分関数は、kの二乗に比例する項と一乗に比例する項に分離する。仮に、
という形になってたら、となるので、非線形パラメータを決定しなくていい。そして、変分関数は
に帰着する。は、線形パラメータ
に依存する関数。実際に計算すると、結局、4次の同次式/4次の同次式という形になって、それほど簡単でもないけど。
Hylleraasが当時、どういう方法で、非線形最適化を計算したのか、論文にも詳細が書かれてなくて、ハッキリとはしないが、何らかの勾配法を使ったと思われる。線形パラメータは、定数項以外は、0に近いので、比較的見つけやすかったのだと思う。
変分関数の計算には
として、以下の積分を計算する必要がある。
これらの積分値は全部解析的に出るけど、書くと長いので省略。
以下に、Hylleraasの計算を追試するための実装を作った。非線形最適化は、scipy.optimizeに丸投げ。Hylleraasの論文の式(25)には、-1.4516という数値が書いてあって、Hylleraasは、4(Ry)が1になるように、エネルギーを無次元化している(式(2)の直後)ので、-2.9032(hartree)程度に相当する。一方、同じ条件(2次以下の6項を使用)で、私の計算結果は、-2.903 329(hartree)となり、合ってるっぽい。
4次までの項を全部入れると、-2.903 713(hartree)になる(scipyが収束してるか怪しいけど)。厳密値は、-2.903 724...(hartree)になるらしいけど、Hylleraasの試行関数では、項数を増やしても、なかなか改善しない。木下論文には、39項使用した最良の結果として、2.903 722 5という数値が書いてある。
上の計算値は、核質量補正が入ってないけど、
Ionization Potential of the Helium Atom
https://arxiv.org/abs/physics/0105108
には、非相対論的エネルギーの値として、2.903 304 557 727 940 23(1)というのが記載されている。核質量補正ありだと、こんなものになるのだろう。
Atomic Spectra Database
https://dx.doi.org/10.18434/T4W30F
で実験値を調べると、2.903 385 87...(hartree)となるので、核補正なしでも、誤差1ミリハートーリー未満は達成できている。
import math
import numpy as np
import scipy.optimize
"""
\int_{0}^_{\infty} ds \int_{0}^{s} du \int_{0}^{u} dt e^{-s} a^{p} t^{q} u^{r}
"""
def T(p,q,r):
if p<0 or q<0 or r<0:return 0
return math.factorial(p+q+r+2)/((q+1)*(q+r+2))
def N(I,J):
ret = T(I[0]+J[0]+2 , I[1]+J[1] , I[2]+J[2]+1)
ret -= T(I[0]+J[0] , I[1]+J[1]+2 , I[2]+J[2]+1)
return ret
def L(I,J):
ret = 2*T(I[0]+J[0]+1 , I[1]+J[1] , I[2]+J[2]+1)
ret -= T(I[0]+J[0]+2 , I[1]+J[1] , I[2]+J[2])/4
ret += T(I[0]+J[0] , I[1]+J[1]+2 , I[2]+J[2])/4
return ret
def M(I,J):
pi,qi,ri = I
pj,qj,rj = J
alpha = 0.5
ret = alpha*alpha*( T(pi+pj+2 , qi+qj , ri+rj+1) - T(pi+pj , qi+qj+2 , ri+rj+1))
ret -= alpha*(pi+pj)*(T(pi+pj+1 , qi+qj , ri+rj+1) - T(pi+pj-1 , qi+qj+2 , ri+rj+1))
ret += pi*pj*(T(pi+pj , qi+qj , ri+rj+1) - T(pi+pj-2 , qi+qj+2 , ri+rj+1))
ret += qi*qj*(T(pi+pj+2 , qi+qj-2 , ri+rj+1) - T(pi+pj , qi+qj , ri+rj+1))
ret += ri*rj*(T(pi+pj+2 , qi+qj , ri+rj-1) - T(pi+pj , qi+qj+2 , ri+rj-1))
ret -= 2*alpha*rj * (T(pi+pj+1,qi+qj,ri+rj+1) - T(pi+pj+1,qi+qj+2,ri+rj-1))
ret += 2*pi*rj*(T(pi+pj,qi+qj,ri+rj+1) - T(pi+pj,qi+qj+2,ri+rj-1))
ret += 2*qi*rj*(T(pi+pj+2,qi+qj,ri+rj-1) -T(pi+pj,qi+qj,ri+rj+1))
return ret
## -- calculate helium ground state energy from Hylleraas-type trial function
class Hyl:
def __init__(self , indices):
n = len(indices)
self.Lm = np.zeros( (n,n) )
self.Mm = np.zeros( (n,n) )
self.Nm = np.zeros( (n,n) )
for i,I in enumerate(indices):
for j,J in enumerate(indices):
self.Lm[i,j] = L(I,J)
self.Mm[i,j] = M(I,J)
self.Nm[i,j] = N(I,J)
def __call__(self , cs):
Lval = np.dot(np.dot(self.Lm , cs) , cs)
Mval = np.dot(np.dot(self.Mm , cs) , cs)
Nval = np.dot(np.dot(self.Nm , cs) , cs)
return -4*Lval*Lval/(Mval*Nval) #-- returns in hartree
def generate_indices(max_sum):
ret = []
for loc_sum in range(max_sum+1):
for p in range(loc_sum+1):
rest_sum = loc_sum - p
for q in range(rest_sum+1):
r = rest_sum - q
if q%2==0:ret.append( (p,q,r) )
return ret
## see Hyleraas1929 (22)-(25)
if __name__=="__main__":
indices =[ (0,0,0) , (0,0,1),(0,2,0),(1,0,0),(2,0,0),(0,0,2)]
#indices = generate_indices(4)
h = Hyl(indices)
x0 = np.zeros(len(indices))
x0[0]=1
res = scipy.optimize.minimize(h , x0, options={"maxiter":10000} )
print(h(res.x))
3次元固有値問題の基本解近似法
基本解近似法(a.k.a 代用電荷法)を使ってる文献を見ると、二次元の問題にしか適用されてない。考案されたのが1960年代で、まだ計算機の能力的に2次元問題が中心だったのかもしれないけど、3次元以上でも使えるのか、気になった。
基本解近似法によるクラドニ図形の計算
https://m-a-o.hatenablog.com/entry/2021/08/09/122806
で単位円板に対するDirichlet固有値問題の近似計算をやったので、3次元単位球で同じ計算をやってみる。ヘルムホルツ方程式の基本解が必要だけど、よく知られてる通り、3次元では、
と書ける。
厳密な固有関数は、3次元の場合、
という形で書ける。は球面調和関数。固有値は
で、ベッセル関数
のゼロ点の2乗。
次数が半整数のBessel関数のゼロ点の近似値は、以下のような感じ。10以下の値は、丁度10個ある。
| p=1 | p=2 | p=3 | |
| 1/2 | 3.141592653589793 | 6.283185307179586 | 9.42477796076938 |
| 3/2 | 4.4934094579090641 | 7.72525183693770716 | 10.904121659428898 |
| 5/2 | 5.76345919689454979 | 9.09501133047635515 | |
| 7/2 | 6.9879320005005199 | ||
| 9/2 | 8.182561452571242 | ||
| 11/2 | 9.355812111042746 |
実装は、2次元の時と殆ど同じで、以下のような感じ。
import numpy as np
from scipy.spatial import distance_matrix
import matplotlib.pyplot as plt
def make_points_on_sphere(N):
U1 = np.random.uniform(size = N)
U2 = np.random.uniform(size = N)
X = np.sin(2 * np.pi * U1) * np.cos(2 * np.pi * U2)
Y = np.cos(2 * np.pi * U1) * np.cos(2 * np.pi * U2)
Z = np.sin(2 * np.pi * U2)
return np.stack([X,Y,Z]).T
def make_points_in_ball(N):
U0 = np.random.uniform(size = N)
U1 = np.random.uniform(size = N)
U2 = np.random.uniform(size = N)
X = U0 * np.sin(2 * np.pi * U1) * np.cos(2 * np.pi * U2)
Y = U0 * np.cos(2 * np.pi * U1) * np.cos(2 * np.pi * U2)
Z = U0 * np.sin(2 * np.pi * U2)
return np.stack([X,Y,Z]).T
"""
Ntest : number of test points (distributed in the ball)
Nsrc : number of source points (exist on the outside of the ball)
Nbnd : number of boundary points (distributed on the sphere)
"""
def main(Ntest , Nsrc , Nbnd):
R = 1.6
Delta_k = 1.0
p_ex = np.array([[5.0, 5.0, 5.0]])
test_points = make_points_in_ball(Ntest)
boundary_points = make_points_on_sphere(Nbnd)
source_points = R * make_points_on_sphere(Nsrc)
D_test = distance_matrix(test_points , source_points)
D_test_ex = distance_matrix(test_points , p_ex).reshape((Ntest,))
D_ex = distance_matrix(boundary_points , p_ex).reshape((Nbnd,))
D = distance_matrix(boundary_points , source_points)
istart = 301
iend = 800
eps = 0.01
ks = []
values = []
for i in range(istart , iend):
k = i * eps
ks.append( k )
w = np.exp(1.0j * (k+Delta_k) * D_ex) / D_ex
G = np.exp(1.0j * k * D) / D
A = np.dot(G.T , G)
B = np.dot(G.T , w)
Q = np.linalg.solve(A , -B)
w_test = np.exp(1.0j * (k+Delta_k) * D_test_ex) / D_test_ex
G_test = np.exp(1.0j * k * D_test) / D_test
F = np.linalg.norm( w_test + np.dot(G_test,Q) )
values.append(F)
plt.plot(np.array(ks) , np.log(np.array(values)))
plt.show()
if __name__=="__main__":
np.random.seed(12345)
main(3000,1500,2000)
パラメータは、l=0,p=1,2,3の時の固有関数の値が再現できるかどうかで決めた。点の数が、二次元の時より、かなり多いけど、これくらいないと、厳密解の値を再現できなかった。多分、二次元の時と違って、点をランダムに取ってるのも影響してるっぽい
また、固有値が大きいほど、多くの点を必要とするっぽい。以下は、l=0,p=3で計算した固有関数の(300点における)実部の値を適当に定数倍したものと、厳密解を重ねたもの。l=0の時は、球対称なので、固有関数の値は、原典からの距離rのみに依存するはずで、横軸が、原点からの距離r

で、固有値(の平方根)が、どこに出るか(3.0〜8.0の範囲で)プロットしたのが、以下のグラフ。

竹中曉という(無名の)数学者のこと
表現論と信号処理
https://m-a-o.hatenablog.com/entry/2019/04/01/221232
で、「Laguerre関数のFourier変換は、Wiener rational functionと呼ばれることがある」(正確には、Fourier変換の積分区間は実数全体だけど、Laguerre関数の定義域は非負実数全体なので、後者に合わせることに注意)と書いたけど、これが、Malmquist-Takenaka systemという名前で呼ばれてることもあるのに気付いた。正確には、Malmquist-Takenaka systemは、(複素単位円周上の)直交有理関数系の総称で、Laguerre関数のFourier変換は、その特殊ケースに過ぎないようだけど。
MalmquistもTakenakaも聞いたことない数学者で、Wikipediaでも、それらしい人は見つからない。Malmquistという人は1926年に
Sur la determination dune classe de fonctions analytiques par leurs valeursdans un ensemble donne de poits
という論文を書いたようだけど、電子化されたデータを見つけることができなかった。一方、Takenakaの方は、明らかに日本人っぽい名前だけど、J-stageで論文を見つけることが出来た。
On the Orthogonal Functions and a New Formula of Interpolation
https://doi.org/10.4099/jjm1924.2.0_129
というのがそれで、フルネームは、Takenaka Satoruというらしいが、漢字は分からない。所属は、Siomi Instituteとなっていて、塩見理化学研究所のことだろう。当時の所長は小倉金之助という数学者だったはず。小倉金之助は補間理論とかやってた人で、"Shannonのサンプリング定理"を最初に証明した人と見なされる場合がある。研究テーマ的には、小倉金之助とTakenaka Satoruは、かなり近かったのかもしれない。
J-stageで検索すると、Takenaka Satoruは、1923〜1933年に、30本ほど論文を書いているっぽい。名字の漢字表記は、"竹中"だろうと思って、1920〜30年あたりで全文検索すると、1929年の日本数学物理学会誌の中にある
講演アブストラクト (昭和五年度年會に於けるもの) その2
https://doi.org/10.11429/subutsukaishi1927.3.440
に於いて、「10. 竹中曉君: テーラー級數の一擴張に就て」というのが見つかる。J-stage有能。アブストラクトなので詳細な内容は不明だけど、1930年の論文
A Generalisation of Taylor's Series
https://doi.org/10.4099/jjm1924.7.0_187
と同一の内容なのだろう。
実用上の意義はともかく、Takenaka Satoruの論文扱ってるテーマは、所詮は、一変数関数の理論で、重箱の隅をつつくような話題という気もする。当時の雰囲気がどういうものだったかは分からない。その後の数学の主流になるようなテーマでなかったのは確かで、20世紀数学史というものが書かれるようなことがあったとしても、このような内容にページは割かれないだろう。
ともあれ、漢字が「竹中曉」らしいと分かった。1929年の数学物理学会で、「数学に関するもの」に列挙されている発表者は、森本淸吾、森島太郎、守屋美賀雄、正田建次郎、藤原松三郎、掛谷宗一、清水辰次郎 、竹中曉、竹内端三、辻正次、渡邊義勝、南雲道夫、福原滿洲雄、市田朝次郎 、荻原伸次、高須鶴三郎、寺阪英孝 、渡部重勝、福澤三八の19人で、ja.wikipedia.orgに名前が載ってる人は半分くらい。清水辰次郎は、ja.wikipedia.orgには名前が見当たらないけど、de.wikipedia.orgには載ってる。なんでや。角谷静夫は、清水辰次郎の学生の一人だったと書いてある。
Wikipediaに名前がなくても、どこかしらの教授なり所長など社会的地位の高い職に就いた人が殆どのようで、大体は、何らかの情報が得られる。その中で、"竹中曉"は情報が乏しく、生没年すら分からない。
塩見理化学研究所小史
http://hdl.handle.net/11094/8755
には、昭和6年(1931年)の嘱託研究員として、竹中曉の名前が見える(39ページ下段)。
Webcat plusで検索すると1929年に
初等積分方程式
http://webcatplus.nii.ac.jp/webcatplus/details/book/449683.html
という本を出版している。Webcat plusでは、目次を見られるのみだが、国会図書館デジタルコレクションでは、公開されてなかった。国会図書館つかえねー。
初等積分方程式(国会図書館デジタルコレクション)
https://dl.ndl.go.jp/info:ndljp/pid/1128551
まー、いつの日か公開されるだろう。Webcat plusで、他の著書を見ると、1930年代に「中等教育代數教科書」「新制平面幾何學教科書」「新制平面三角法教科書 : 増課」など、初等数学の本ばかりが出てくるので、1930年代初め頃、数学者をやめたのかもしれない。CiNiiでは、名前の読みが、「タケナカ アキラ」となってたりするけど、多分、誤りだと思う。同じ漢字の別人ということはないだろう。最後の本は、1938年で、それ以後はない。戦争に派兵されて戦死したのかもしれないけど、定かではない。
Google scholarで検索した所、Mamlquist-Takenakaという名前が最初に出てくるのは、1974年の論文
BIORTHOGONAL SYSTEMS OF RATIONAL FUNCTIONS AND BEST APPROXIMATION OF THE CAUCHY KERNEL ON THE REAL AXIS
http://dx.doi.org/10.1070/SM1974v024n03ABEH001918
に於いてだった。著者は、 M M Džrbašjanという人で、当時のソ連圏の人っぽいけど、何者なのかは分からない。Abstract冒頭に
This system is a direct transference from a disk into a half-plane of the well-known orthogonal Malmquist-Takenaka system.
と書かれてるが、本当にwell-knownだったのかは疑問。原文はロシア語らしいので、ソ連では、よく知られてたのかもしれないけど。
Google booksで検索した所、Joseph Walshの1935年の本
Interpolation and Approximation by Rational Functions in the Complex Domain
https://books.google.co.jp/books/about/Interpolation_and_Approximation_by_Ratio.html?id=Pyz3AwAAQBAJ&redir_esc=y
でも、MamlquistとTakenakaに言及があるっぽい。オープンアクセスになってるのは見つからなかったし、買って読む気にはならないので詳細は分からない。Walshは、(MalmquistやTakenakaに比べると)そこそこ有名な解析学者なので、この本を通じて、無名の2人の数学者の名前が残ったことは、ありそうに思える。
ところで、Takenakaの論文や、Walshの本には、特にLaguerre関数への言及はない。彼らは、直交有理関数系の一般論を考えていたけれど、その具体例として、Laguerre関数のFourier変換があることは認識してなかったように思われる。
Wienerが、このタイプの有理関数を書いたのは、
Extrapolation, Interpolation, and Smoothing of Stationary Time Series: With Engineering Applications
https://doi.org/10.7551/mitpress/2946.001.0001
という本のようで、元々は二次大戦中の1942年に書かれたものらしい。オープンアクセスになってるものは見つからなかったが、目次を見る限り、Laguerre関数への言及があり、Amazonでコンテンツの検索をした限りでは、"Malmquist"も"Takenaka"も引っかからなかった。
Lagurre関数のFourier変換を考えた文献として、Lee Yuk-Wingという人の博士論文がある。
Synthesis of electric networks by means of the Fourier tansforms of Laguerre's functions
https://dspace.mit.edu/handle/1721.1/104477
Lagurre関数のFourier変換は、31ページで計算されている。このD論は、1930年付けになっているので、Walshの本より前のもの。
Lee Yuk-Wingという人は、名前を聞いたことがなかったけど、Wikipediaにも名前が載っている。それによると、マカオ生まれで、漢字では、李郁榮と書くらしい。MITで学位取得後、一旦は中国へ帰ったが、二次大戦後、MITに戻り、Wienerと長い間、一緒に仕事をしたそうだ。D論の謝辞にも
Dr. Wiener has contributed profusely to the mathematical theory of this research.
とWienerの名前が挙がっている。Leeの専門は、電気工学で、解析学者たちとは異なる動機から、Laguerre関数のFourier変換を考え、Wienerも、そのことを知っていたのだろう。
謝辞の冒頭に来てるのは、Vannevar Bushで、多分、Leeの指導教官なんだと思う。BushとWienerは、MIT繋がりで知り合いだったそうだ。
そんなわけで、Laguerre多項式のFourier変換/"Wienerの有理関数"は、Leeの有理関数か、Lee-Wienerの有理関数と呼ぶのが適切っぽい。
ついでに、Laguerre多項式とHermite多項式は、それぞれLaguerreの1879年の論文、Hermiteの1864年の論文に由来するそうだが、どちらの直交多項式も、Chebyshevの1859年の論文に書かれている。その論文は、Œuvres de P. L. Tchebychef, 第1巻の501〜508ページに収録されていて、Google booksで読むことが出来る。
Sur le développement des fonctions à une seule variable
https://books.google.co.jp/books?id=V8RJAQAAMAAJ&pg=PA501
Lagurreの論文は、以下で公開されている全集1巻の428〜437ページに収録されてる。
Edmond Nicolas Laguerre - Œuvres complètes, tome 1
http://sites.mathdoc.fr/cgi-bin/oetoc?id=OE_LAGUERRE__1
Laguerreは、ある種の指数積分(今日では、E_1関数、s=0の不完全ガンマ関数などと呼ばれてるもの)を考察する中で、Laguerre多項式を発見したっぽい。この積分を考えた動機は分からないけど、印象的な恒等式を見つけるのが目的ではなく、特殊関数の数値計算のためのありふれた研究の一つだったんだろう。
Hermite多項式の方は、もっと古く、本質的には、Laplaceによって1810年には発見されてたらしい。
Pierre-Simon Laplace - Œuvres complètes, tome 12
http://sites.mathdoc.fr/cgi-bin/oetoc?id=OE_LAPLACE__12
の357〜412ページ"Mémoire sur les intégrales définies et leur application aux probabilités, et spécialement à la recherche du milieu qu'il faut choisir entre les résultats des observations"が該当論文らしいが、implicitに表れてるだけで、分かりにくい。なんか確率論の問題を考えてる。
詳細は読んでないけど、この中で、Laplaceは、今ではFokker-Planck方程式と呼ばれている偏微分方程式と同一の偏微分方程式
を書いている(377ページ)。
Laplace and the origin of the Ornstein-Uhlenbeck process
https://doi.org/10.3150/bj/1178291723
に、解説がある。Laplaceによる導出は、100年以上に渡って正当化されず、批判されていたそうだ。
Laplaceの論文より数年前の1807年に、"Mémoire sur la propagation de la chaleur dans les corps solides"で、Joseph Fourierは、確率論とは何の関係もなさそうな熱伝導の問題から、(多分)初めて熱方程式を書いた。"random walk"と熱方程式を同時に取り上げた最初の文献は、多分、Bachelierの1900年の論文と思われる。Fourierの1807年の論文は、以下で読める。
Joseph Fourier - Œuvres complètes, tome 2
http://sites.mathdoc.fr/cgi-bin/oetoc?id=OE_FOURIER__2
(線形)発展方程式の一般論は20世紀に整備された。"発展方程式"という呼称を最初に使ったのは、L.Schwartzだそうだ(勿論、フランス語で)。Laplaceの時代には、議論の見通しはよくなかっただろう。Laplaceの発展方程式を解くのは、量子調和振動子のシュレディンガー方程式を解くのと、数学的には等価なので、今では大学一年生の演習問題レベルである。Laplaceの発展方程式は、生成作用素の固有関数が
を使って書ける。実際、
から、
となる。LaplaceがHermite多項式に到達した理由は、このように理解できる。特に、この偏微分方程式の基本解が、Hermite関数によって展開できる。現在、Fokker-Planck方程式の基本解は、Mehler kernelと呼ばれることがある。
Mehler kernelは、1866年に、Mehlerが
Ueber die Entwicklung einer Function von beliebig vielen Variablen nach Laplaceschen Functionen höherer Ordnung
http://www.digizeitschriften.de/dms/resolveppn/?PID=GDZPPN002152975
で書いたもので、確率論とは異なる動機から、この基本解を考えたっぽい。Mehlerは、
という偏微分方程式の"基本解"を導いた。と変数変換すれば、発展方程式の形になる。Mehlerは基本解を計算しただけでなく、Hermite多項式によって展開している。
上の解説によれば、Fokker-Planck方程式の基本解を明示的に書いた初期の人は、Markov(1915)らしい。この時期には、ブラウン運動と関連して、Fokker-Planck方程式が様々な人に研究されてたようなので、同様の結果に到達していた人は、他にもいたかもしれない。
いずれにしても、Hermite多項式は、複数の人が独立に発見したので、20世紀初頭のロシア人(MarkovやSteklov)は、Hermite多項式をLaplace-Chebyshev-Hermite多項式と呼んだこともあったそうだ。けれど、長いせいか、世界的には、Hermite多項式で定着してしまっている。